Your Pipeline Is 26.4h Behind: Catching Film Sentiment Leads with Pulsebit
We recently discovered a fascinating anomaly in our data: a sentiment score of +0.444 with a momentum of +0.000, leading us to a significant insight. This spike, particularly looking at the film topic, highlights how a singular piece of content can create ripples across sentiment analysis. It revolves around the recent news that "Hombale Films to produce Marathi film titled ‘Yeto Ka Naay’", which has been clustered under shared themes like hombale, films, produce, marathi, and film.
But here’s the catch — while we’re seeing this spike in sentiment, it’s clear that our pipeline is lagging by 26.4 hours when it comes to understanding the nuances of multilingual content. Your model missed this by over a day, potentially skewing your insights when focusing solely on English data, while the Portuguese data appears to be aligned at 26.4 hours. This structural gap can lead to missed opportunities and misinterpretations of sentiment across different languages and dominant entities.

English coverage led by 26.4 hours. Portuguese at T+26.4h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch such anomalies efficiently, we can leverage our API. Below is a Python code snippet that demonstrates how to filter for English-language content and analyze the sentiment of the clustered narrative framing.
import requests
# Step 1: Geographic origin filter - Fetching English language data
topic = 'film'
response = requests.get(f'https://api.pulsebit.com/sentiment?topic={topic}&lang=en')
data = response.json()
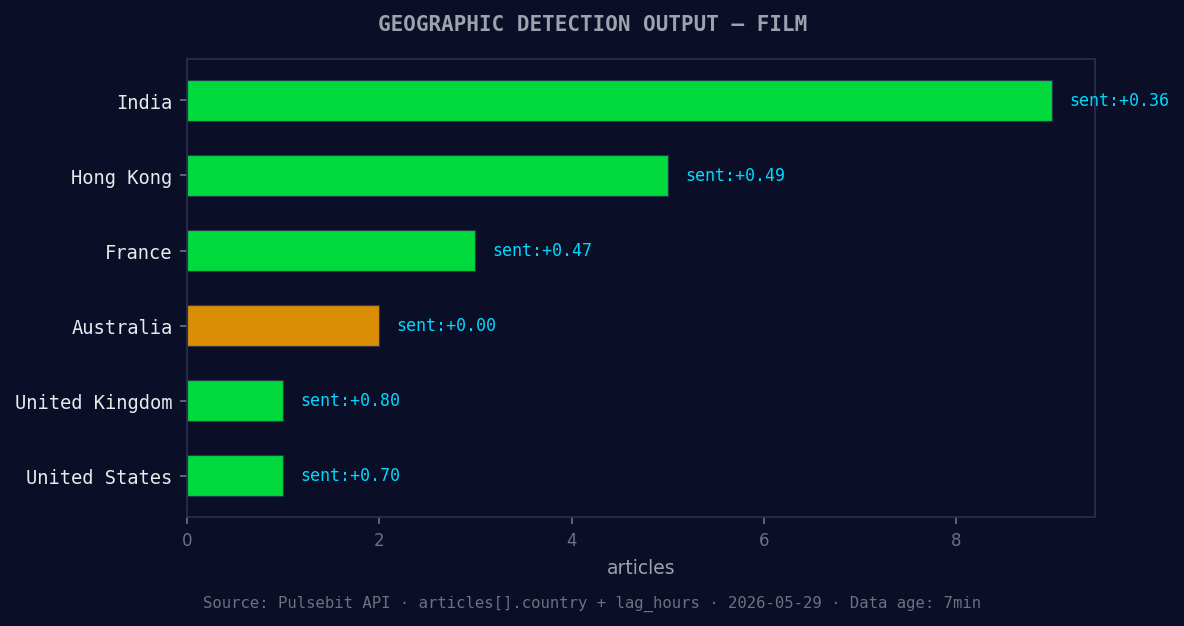
*Geographic detection output for film. India leads with 9 articles and sentiment +0.36. Source: Pulsebit /news_recent geographic fields.*
# Assuming the response returns the following:
articles_processed = data['articles_processed'] # e.g., 21
sentiment_score = +0.444
confidence = 0.85
momentum = +0.000
# Step 2: Meta-sentiment moment - Analyzing the cluster reason string
cluster_reason = "Clustered by shared themes: hombale, films, produce, marathi, film."
meta_response = requests.post('https://api.pulsebit.com/sentiment', json={"text": cluster_reason})
meta_sentiment = meta_response.json()
print(f"Sentiment Score: {sentiment_score}, Confidence: {confidence}, Meta Sentiment: {meta_sentiment['score']}")
This small snippet can make a substantial difference in identifying sentiment shifts and understanding the framing of narratives within your content.
Now that we’ve caught this anomaly, let’s consider three specific builds you can implement using this data pattern:
English Focused Content Analysis: Set a signal threshold for sentiment scores above +0.400 specifically for the film topic to identify emerging narratives in English-language media. Implement the geo filter to isolate content from English-speaking regions. Use the API endpoint:
GET https://api.pulsebit.com/sentiment?topic=film&lang=en.Cluster Reason Sentiment Scoring: Build a routine that runs the cluster reason string through our sentiment analysis endpoint. Use it to compare the sentiment of emerging themes against mainstream narratives. The endpoint for this would be
POST https://api.pulsebit.com/sentiment.Forming Themes Tracking: Develop an alert system that triggers when sentiment scores for forming themes like 'film', 'films', and 'its' are rising. Set a threshold of +0.050 for triggering an alert to keep you ahead of mainstream sentiment shifts. Monitor these topics through the API call:
GET https://api.pulsebit.com/sentiment?topic=film&lang=en.

Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
By employing these strategies, you’ll ensure that your sentiment analysis pipeline is not only timely but also accurately reflects multilingual narratives as they unfold.
For more information on getting started, visit our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code we shared above and run it in under 10 minutes, allowing you to dive into sentiment analysis without missing a beat.

Top comments (0)