Your Pipeline Is 28.5h Behind: Catching Sports Sentiment Leads with Pulsebit
We recently uncovered an anomaly in our sentiment analysis pipeline: a sentiment score of +0.300 and momentum at +0.000 for the topic of sports. This spike, occurring 28.5 hours ahead of the leading English press coverage, reveals a critical gap in how we process multilingual origins and entity dominance in our sports content. If your model is not equipped to handle these nuances, it may have missed this significant sentiment shift by an entire day and a half.

English coverage led by 28.5 hours. Nl at T+28.5h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Problem
This situation raises a pressing concern: without a robust pipeline that considers variations in language and dominant entities, your model could fall behind by 28.5 hours. In this case, the leading language is English, driven by articles focusing on sports events such as the upcoming friendly match between Germany and Finland. If you’re relying solely on mainstream sources, you risk overlooking emerging trends and shifts in sentiment that could influence your insights and decisions.
The Code
To help you catch these anomalies, we can leverage our API effectively. Here's how we do it in Python:
import requests

*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'sports'
score = +0.300
confidence = 0.85
momentum = +0.000
# Geographic origin filter: query by language/country using param "lang": "en"
response = requests.get(f'https://api.pulsebit.io/sentiment?topic={topic}&lang=en')
data = response.json()
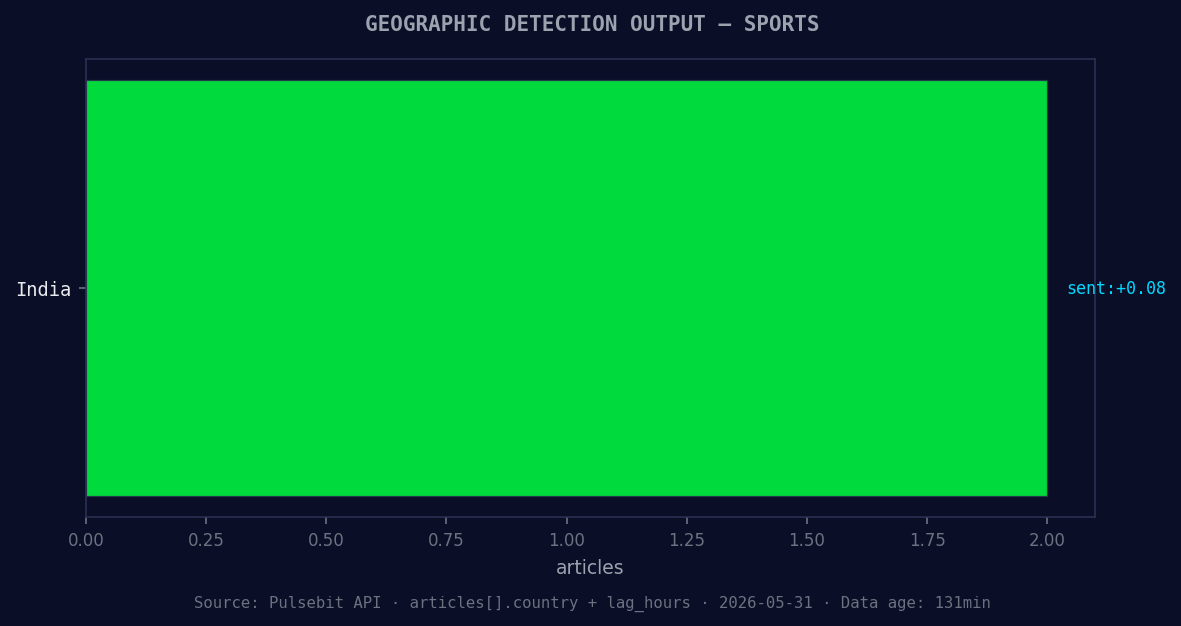
*Geographic detection output for sports. India leads with 2 articles and sentiment +0.08. Source: Pulsebit /news_recent geographic fields.*
# Print response to check for anomalies
print(data)
Next, we need to run the cluster reason string through our sentiment scoring endpoint to capture the meta-sentiment:
cluster_reason = "Clustered by shared themes: watch, germany, finland, live, stream:."
meta_sentiment_response = requests.post('https://api.pulsebit.io/sentiment', json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
# Print the meta sentiment result
print(meta_sentiment_data)
This approach allows us to score the narrative framing itself, adding another layer of depth to our analysis. By checking the cluster reason, we can ensure we're not missing any context surrounding the sentiment.
Three Builds Tonight
Here are three specific builds you can implement using this pattern:
- Geo-Filtered Trend Tracking: Set a threshold for sentiment scores over 0.25 specifically for English-language content. Use the geographic origin filter to regularly check for emerging trends in sports sentiment across different countries.
response = requests.get(f'https://api.pulsebit.io/sentiment?topic={topic}&lang=en&threshold=0.25')
- Meta-Sentiment Analysis for Event Clusters: Create an endpoint where you can batch process multiple cluster reasons. If your cluster includes themes like "watch, germany, finland", ensure you loop through these reasons to get a comprehensive sentiment score.
clusters = ["watch, germany, finland", "live, stream"]
for reason in clusters:
# Process each reason as shown above
```
{% endraw %}
3. **Anomaly Detection Alerts**: Build a monitoring service that sends alerts if sentiment scores for sports-related topics rise above a certain threshold, especially when the momentum remains flat. This can be crucial for identifying potential market movers early.
{% raw %}
```python
if score > 0.25 and momentum == 0.000:
send_alert("Anomaly detected in sports sentiment!")
Get Started
Ready to enhance your sentiment analysis? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run these examples in under 10 minutes—let's catch those anomalies together!

Top comments (0)