Your model just missed a significant anomaly: a 24h momentum spike of +0.950 in the stock market sentiment. This isn't just a minor deviation; it reflects a substantial shift in sentiment that you need to capture. The leading language of the articles driving this momentum is English, with a notable 27.1h lead time. The implication is clear: if your pipeline isn't set up to handle multilingual origins or prioritize dominant entities, you're likely 27.1 hours behind on pivotal market insights.

English coverage led by 27.1 hours. No at T+27.1h. Confidence scores: English 0.80, French 0.80, Spanish 0.80 Source: Pulsebit /sentiment_by_lang.
This gap reveals a fundamental flaw in your data pipeline. Sentiment analysis that disregards language and entity dominance can lead to missed opportunities. Your model missed this by 27.1 hours. In a world where information travels at the speed of light, lagging behind could mean the difference between capitalizing on a trend and watching it slip away. The leading language in this case? English. This is a wake-up call for developers who are serious about making data-driven decisions.
To catch this anomaly efficiently, we can leverage our API with a few lines of Python code. Here’s how we can do it:
import requests
*Left: Python GET /news_semantic call for 'stock market'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define your parameters for sentiment analysis
topic = 'stock market'
score = +0.535
confidence = 0.80
momentum = +0.950
# Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": topic,
"lang": "en"
}
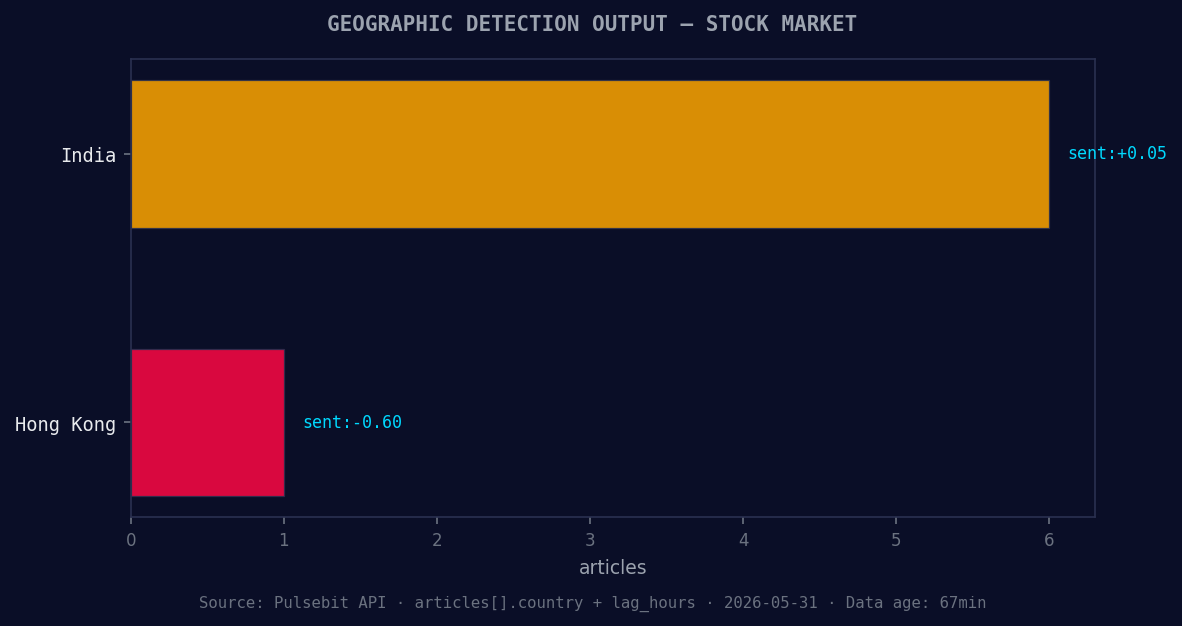
*Geographic detection output for stock market. India leads with 6 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: stock, market, may, about, break."
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_response = requests.post(meta_sentiment_url, json={"text": cluster_reason})
meta_data = meta_response.json()
print(meta_data)
In this code, we first filter our sentiment analysis by the English language to ensure we’re capturing the most relevant data. Next, we run the cluster reason string through our sentiment endpoint to score the narrative framing itself. This dual approach allows us to refine the context around our stock market sentiment and understand the underlying themes.
Now, let's explore three specific builds you can implement with this pattern. First, set up a real-time alert for any momentum spikes exceeding a threshold of +0.700. This will help you catch significant sentiment shifts early. Next, create a monitoring dashboard that displays sentiment changes across different geographical regions, filtering specifically for the English-speaking cluster. This could be as simple as querying our API with the geo filter for various regions. Finally, utilize the meta-sentiment loop to enrich your content strategy by analyzing how narratives evolve over time. For example, track the sentiment around the themes forming in the articles, like "stock(+0.00), market(+0.00), google(+0.00)" versus the mainstream "stock, market, may." This can provide you with actionable insights for your content strategy.
To get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste this code and run it in under 10 minutes. Don’t let the next sentiment shift pass you by.

Top comments (0)