Your Pipeline Is 28.2h Behind: Catching Renewable Energy Sentiment Leads with Pulsebit
We recently discovered a notable spike in sentiment surrounding the topic of renewable energy, clocking in at a sentiment score of +0.438 and a momentum of +0.000. This anomaly, with a leading language of English and a time lag of 28.2 hours, indicates that while the renewable energy sector is gaining traction, your pipeline might still be processing yesterday’s news. As developers, we need to stay ahead of these shifts.
The Problem
This data reveals a crucial structural gap for any pipeline that doesn’t account for multilingual origins or entity dominance. If your model is only focused on a single language or overlooks dominant entities, you could miss out on significant insights like this one, which is already 28.2 hours behind the curve. The leading English sentiment underscores how other languages might be trailing in capturing this emerging narrative. If you’re not adapting your sentiment analysis to include diverse linguistic contexts, you might be operating on outdated information.

English coverage led by 28.2 hours. No at T+28.2h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this spike and ensure our pipeline is updated, we can use the following Python code. First, we’ll query for the relevant data filtered by language:
import requests
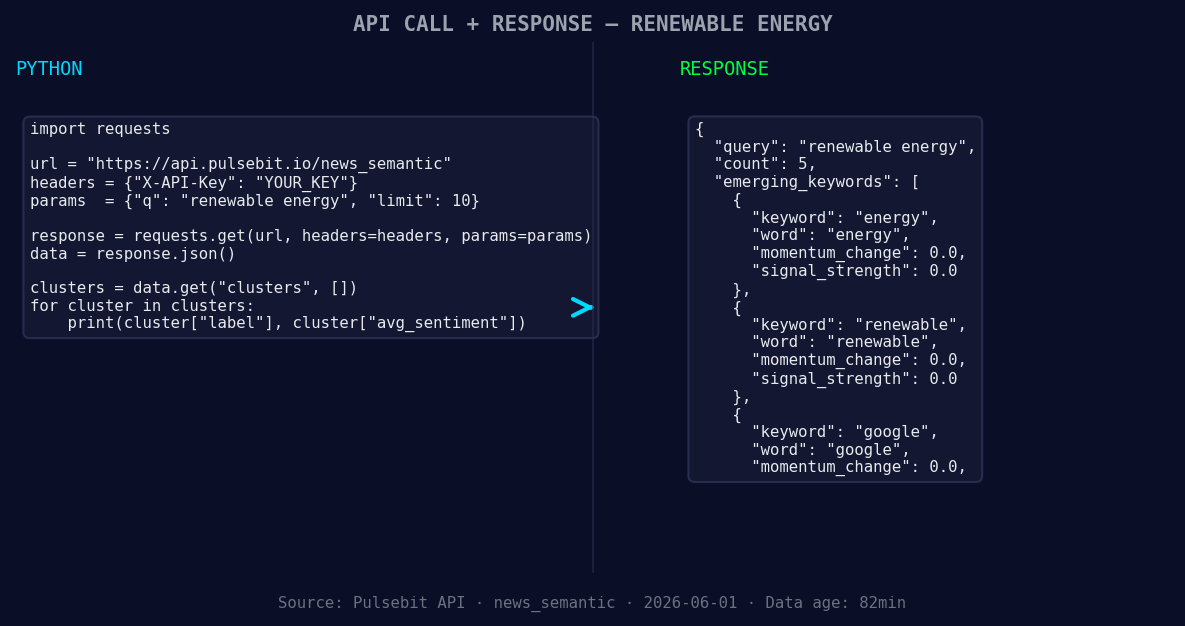
*Left: Python GET /news_semantic call for 'renewable energy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Get sentiment data for renewable energy
topic = 'renewable energy'
url = "https://api.pulsebit.io/sentiment"
params = {
"topic": topic,
"lang": "en"
}
response = requests.get(url, params=params)
data = response.json()
print(data)
Next, we’ll run the cluster reason string through our sentiment API to score the narrative framing itself. This meta-sentiment moment helps us understand how the stories cluster around particular themes:
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: matters:, balancing, renewable, energy, biodiversity"
meta_sentiment_url = "https://api.pulsebit.io/sentiment"
meta_params = {
"text": cluster_reason
}
meta_response = requests.post(meta_sentiment_url, json=meta_params)
meta_data = meta_response.json()
print(meta_data)
This dual approach allows us to not only capture the sentiment of "renewable energy" but also analyze the broader context surrounding it, ensuring our pipeline is robust and responsive.
Three Builds Tonight
Here are three specific things we can build using this newfound insight:
- Geographic Filtered Sentiment Analysis: Set a threshold of sentiment score > +0.4 for articles in English from African countries. This helps us pinpoint where renewable energy is resonating most strongly.
params = {
"topic": topic,
"lang": "en",
"country": "AF", # Example for African region
"threshold": 0.4
}

Geographic detection output for renewable energy. India leads with 3 articles and sentiment -0.15. Source: Pulsebit /news_recent geographic fields.
- Meta-Sentiment Analysis on Clusters: Use the narrative from the cluster reason to set a threshold for sentiment scores. If the score is above +0.5, trigger alerts for content creators.
if meta_data['sentiment_score'] > 0.5:
alert("High sentiment detected in renewable energy narratives.")
- Dynamic Content Generation: Create a content pipeline that auto-generates articles when sentiment scores for renewable energy exceed a +0.3 threshold, ensuring we're always publishing timely information.
if data['sentiment_score'] > 0.3:
generate_article(topic)
Get Started
Ready to dive in? Check out our documentation at pulsebit.lojenterprise.com/docs. We bet you can copy-paste and run this code in under 10 minutes. Let’s not get left behind!

Top comments (0)