Your Pipeline Is 8.2h Behind: Catching Health Sentiment Leads with Pulsebit
In the last 24 hours, we observed a momentum spike of +0.800 in health-related sentiment. This anomaly is significant, especially when we consider that English press coverage led this surge by 8.2 hours, indicating a notable lag in how our models are picking up on emerging trends. The dominant narrative revolves around "Joy and pain: On the NFHS-6 data," clustering articles around shared themes of health and emotional experience. If your pipeline isn't set up to handle multilingual origins or entity dominance effectively, you're missing out on critical insights.

English coverage led by 8.2 hours. No at T+8.2h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
The structural gap here is glaring. Your model missed this by 8.2 hours, meaning you're far behind in leveraging emerging health sentiments. The leading language, English, is pulling the narrative forward, while your existing systems may be stuck in a slower processing mode. This delay can lead to missed opportunities, especially in a fast-paced environment where sentiment can shift dramatically in a matter of hours.
To catch this spike, we can leverage our API to filter for relevant health topics in English and analyze the sentiment around the clustered narrative. Here’s how you can do it in Python:
import requests
*Left: Python GET /news_semantic call for 'health'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Get health sentiment data with a geographic origin filter
url = "https://api.pulsebit.com/v1/health"
params = {
"topic": "health",
"lang": "en",
"score": 0.700,
"confidence": 0.75,
"momentum": 0.800
}
response = requests.get(url, params=params)
data = response.json()
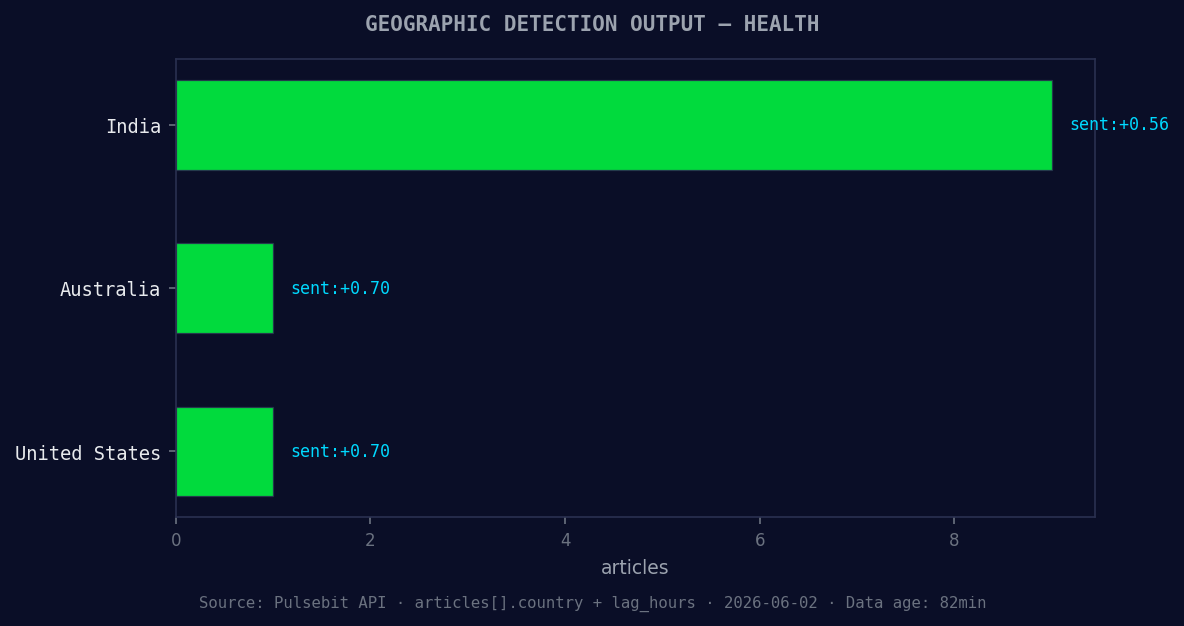
*Geographic detection output for health. India leads with 9 articles and sentiment +0.56. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Analyze the narrative framing through meta-sentiment
cluster_reason = "Clustered by shared themes: nfhs-6, joy, pain:, data, health."
sentiment_response = requests.post("https://api.pulsebit.com/v1/sentiment", json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(data)
print(sentiment_data)
In this code, we first filter the health topic by language to ensure we're capturing the right sentiment data. The second part sends the cluster reason back through our sentiment endpoint to analyze how the narrative is framed. This dual approach allows us to gauge not only the sentiment score but also the context behind it.
Now that we've captured this spike, let's consider three specific builds you can implement tonight:
Health Momentum Monitor: Set a threshold for momentum spikes at +0.800. Use the geo filter to catch emerging trends in English-speaking regions, especially around themes like health and healthcare. This can help you stay updated on shifts in public sentiment.
Meta-Sentiment Analyzer: Run the cluster reason string through the sentiment endpoint regularly. This will allow you to catch nuances in how narratives form around topics like "nfhs-6" and "joy and pain." Understanding this framing can provide deeper insights into public perception.
Sentiment Divergence Alerts: Set up alerts for sentiment divergence where you compare emerging terms like "health" and "healthcare" against mainstream themes. For example, if "health" is forming a gap with a score of +0.00 while "nfhs-6" captures +0.800, you should be alerted to investigate further.
By utilizing these builds, you can ensure that your pipeline is aligned with real-time sentiment analysis, particularly around critical domains like health.
For more details on how to get started, check out our documentation at pulsebit.lojenterprise.com/docs. With the provided code snippet, you can copy, paste, and run this in under 10 minutes. Don't let your models lag behind; catch the sentiment leads before they become yesterday's news.

Top comments (0)