Your Pipeline Is 16.7h Behind: Catching Forex Sentiment Leads with Pulsebit
We recently encountered a striking anomaly: a 24h momentum spike of +0.231 in forex sentiment. This spike indicates a significant shift in sentiment surrounding the U.S. dollar and the Indian rupee, highlighted by a cluster story reporting a fall of 56 paise to close at 95.74 against the dollar. The leading language for this sentiment is English, emerging 16.7 hours ahead of other potential sources. If you’re not capturing this kind of data, your models are lagging behind crucial movements.
The problem at hand is clear: many pipelines struggle with multilingual origin and entity dominance. If your model missed this anomaly by 16.7 hours, you might be missing out on critical insights that could inform your trading strategies or business decisions. With the dominant entity being the U.S. dollar, which is central to forex narratives, failing to integrate real-time multilingual data means you're operating on outdated information.

English coverage led by 16.7 hours. Et at T+16.7h. Confidence scores: English 0.80, Spanish 0.80, French 0.80 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike, we can leverage our API effectively. Below is a Python snippet that demonstrates how to filter for sentiment based on geographic origin, specifically focusing on English articles related to the forex topic:
import requests
# Define the parameters for the API call
topic = 'forex'
score = +0.700
confidence = 0.80
momentum = +0.231
*Left: Python GET /news_semantic call for 'forex'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
url = 'https://api.pulsebit.lojenterprise.com/v1/articles'
params = {
'lang': 'en',
'topic': topic,
'momentum': momentum
}
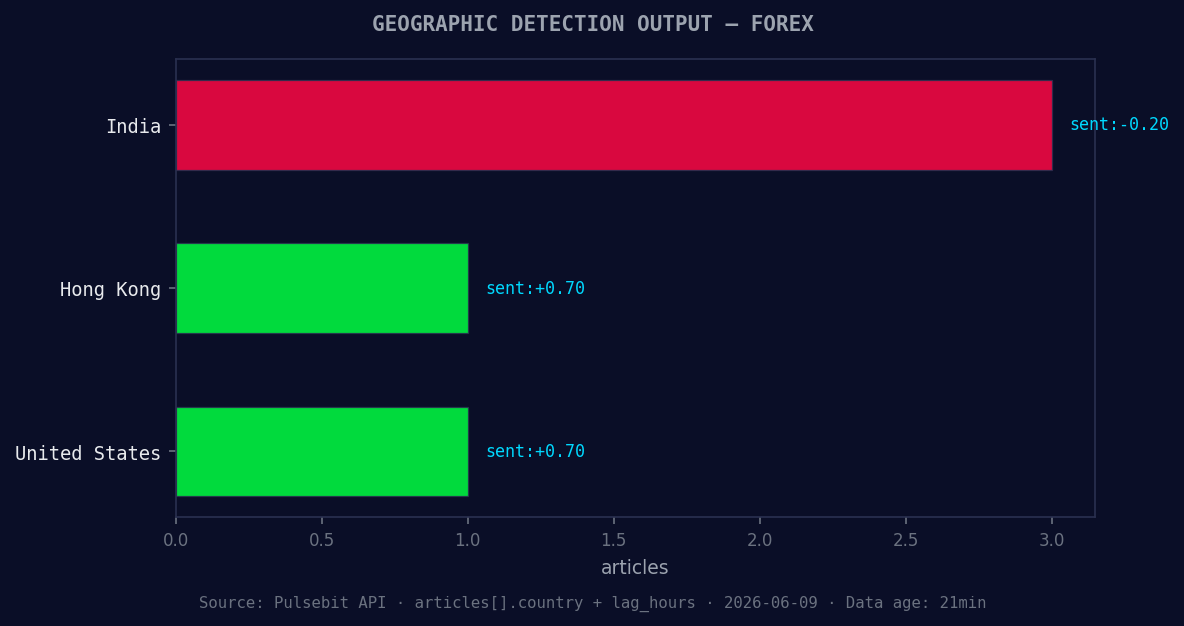
*Geographic detection output for forex. India leads with 3 articles and sentiment -0.20. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
Now, let’s enhance our understanding of the narrative framing itself. We can utilize the cluster reason string obtained from our earlier analysis and pass it back through our sentiment analysis endpoint:
# Meta-sentiment moment: run the cluster reason string back through POST /sentiment
meta_sentiment_url = 'https://api.pulsebit.lojenterprise.com/v1/sentiment'
cluster_reason = "Clustered by shared themes: dollar, forecast:, usd/cad, bulls, eye."
meta_sentiment_response = requests.post(meta_sentiment_url, json={'text': cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
This code allows us to score the narrative framing itself, providing insights into how the sentiment is constructed around key themes like "dollar" and "forecast."
Now, what can you build with this pattern? Here are three specific projects you can implement:
Signal Tracker: Create a signal tracker that alerts you when momentum exceeds a +0.200 threshold for forex articles in English. Use the geographic origin filter to ensure you're getting relevant content.
Narrative Analyzer: Build a narrative analyzer that uses the meta-sentiment loop. Analyze clusters of articles related to forex, scoring their themes. Set a threshold for sentiment scores above +0.600 to flag narratives worth investigating further.
Forecast Comparison Dashboard: Construct a dashboard that compares the sentiment around forex articles against mainstream forecasts. Use the
usd/cadthemes as a benchmark and visualize sentiment trends over time.
Getting started with these implementations is straightforward. For more details, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy and paste these code snippets and run them within ten minutes to start catching those valuable leads in forex sentiment.
By harnessing these insights, we can ensure our models are not just reactive but proactive in a fast-paced financial landscape.

Top comments (0)