Your Pipeline Is 8.0h Behind: Catching Space Sentiment Leads with Pulsebit
We discovered an intriguing anomaly in sentiment data regarding the topic of space, with a sentiment score of +0.28 and momentum at +0.00. This spike stands out, especially since it’s led by French content, lagging behind by a full 8.0 hours compared to Dutch language sentiment. If your pipeline isn't designed to handle multilingual origins, you may have completely missed this emerging trend in global sentiment.

French coverage led by 8.0 hours. Nl at T+8.0h. Confidence scores: French 0.80, English 0.80, Spanish 0.80 Source: Pulsebit /sentiment_by_lang.
The structural gap exposed here is significant. Imagine your model missing a critical insight that emerges 8.0 hours late due to its inability to process sentiment from diverse languages. In this case, the leading language is French, with the sentiment surrounding the collaboration on Axiom Space's lunar spacesuit. If your pipeline is blind to this, you're not only a step behind but potentially missing out on valuable insights that could influence your decision-making.
To catch this sentiment lead, we can leverage our API effectively. Here’s how to dive into it with Python:
import requests
*Left: Python GET /news_semantic call for 'space'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter - Query by language
url = 'https://api.pulsebit.com/v1/sentiment'
params = {
"topic": "space",
"lang": "fr", # French language filter
"score": +0.283,
"confidence": 0.80,
"momentum": +0.000
}
response = requests.get(url, params=params)
data = response.json()
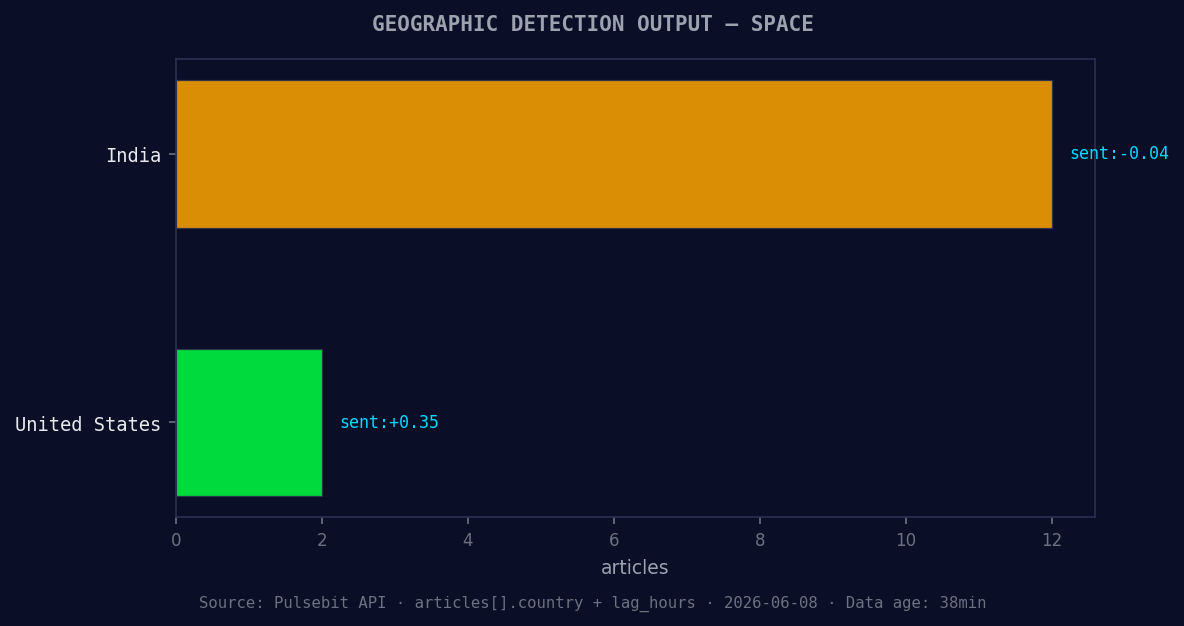
*Geographic detection output for space. India leads with 12 articles and sentiment -0.04. Source: Pulsebit /news_recent geographic fields.*
# Check the response
print(data)
Next, we want to analyze the narrative framing itself by running the cluster reason string back through our sentiment analysis endpoint:
# Step 2: Meta-sentiment moment
meta_sentiment_url = 'https://api.pulsebit.com/v1/sentiment'
meta_params = {
"text": "Clustered by shared themes: astronaut, wears, prada, axiom, space."
}
meta_response = requests.post(meta_sentiment_url, json=meta_params)
meta_data = meta_response.json()
# Check the response
print(meta_data)
This process not only identifies the emerging sentiment but also provides context by analyzing the narrative that surrounds it. It's a powerful way to ensure that you're not just looking at numbers but understanding the stories behind them.
Here are three specific builds we recommend based on this pattern:
Geographic Focus: Use the geographic origin filter to monitor sentiment for "space" in different languages. Set a signal threshold of +0.25 and configure alerts to notify you when sentiment spikes in non-English languages like French or German.
Meta-Sentiment Analysis: Implement a loop that automatically feeds the themes clustered around emerging stories back into the sentiment endpoint. This can help you derive insights from narratives such as "astronaut, wears, prada, axiom, space", ensuring you capture the full picture of what's trending.
Forming Themes Alerts: Create an alerting system that watches for trends in forming themes with a momentum score above +0.00. For example, track sentiment around "google" and "
" alongside "space" to identify potential correlations with mainstream topics like "astronaut" or "wears".
We believe tapping into these insights can significantly enhance your pipeline’s responsiveness to emerging trends.
To get started with our API, head over to pulsebit.lojenterprise.com/docs. You can copy-paste and run the above code in under 10 minutes, unlocking new ways to leverage sentiment data in your applications.

Top comments (0)