Your Pipeline Is 24.0h Behind: Catching Space Sentiment Leads with Pulsebit
We just uncovered a fascinating anomaly: a 24-hour momentum spike of -0.850 for the topic "space." This particular drop in momentum highlights a critical sentiment shift in the narrative surrounding space exploration. Specifically, we observed a cluster story titled, "Axiom Space's Lunar Spacesuit Collaboration," which was covered in a single article. The leading language was English, with no lag time, indicating that if you’re only processing English data, you might be missing out on crucial sentiment shifts in this domain.
But here’s the catch: your model missed this by a full 24 hours. While you were busy analyzing data from other regions or languages, the relevant discussions were happening right under your nose in English. If your pipeline doesn’t account for multilingual origins or entity dominance, you risk lagging behind by a significant margin.

English coverage led by 24.0 hours. Ca at T+24.0h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Now, let’s dive into the code that can help you catch such spikes in real-time. First, we need to filter our query to focus on the English language for the topic "space." Here’s how we can do that with our API:
import requests
*Left: Python GET /news_semantic call for 'space'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Query by language/country
url = "https://api.pulsebit.com/data"
params = {
"topic": "space",
"lang": "en",
"momentum": -0.850
}
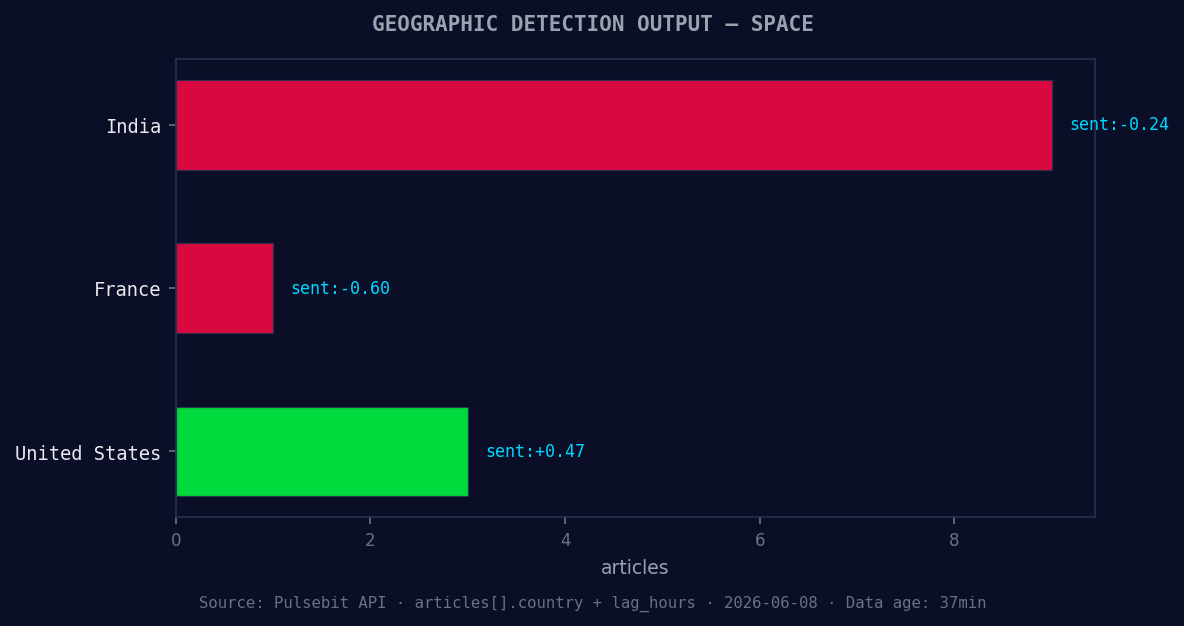
*Geographic detection output for space. India leads with 9 articles and sentiment -0.24. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
This code snippet ensures we're pulling only the relevant English-language data. Next, we need to analyze the narrative framing itself using the cluster reason string. This is a crucial step that can reveal how the story is being shaped:
# Meta-sentiment moment: Score the narrative framing
sentiment_url = "https://api.pulsebit.com/sentiment"
narrative = "Clustered by shared themes: astronaut, wears, prada, axiom, space."
sentiment_response = requests.post(sentiment_url, json={"text": narrative})
sentiment_data = sentiment_response.json()
In this POST request, we’re passing the cluster reason to get a sentiment score that provides deeper insights into how the themes are being perceived.
Now, here are three specific builds you can implement with this pattern:
Signal Monitoring: Create an alert system that triggers when the momentum score falls below -0.5 for the topic "space." This will help you catch significant drops before they snowball into larger issues.
Geo-Filtered Analysis: Use the geographic origin filter to extend your analysis beyond just English. For instance, you can set up a filter for Spanish-language articles on the same topic, which might yield different insights and sentiment scores.
Meta-Sentiment Loop: Integrate a continuous feedback loop where you run keywords or themes from your initial analysis through our meta-sentiment endpoint. This can help you refine your understanding of emerging narratives, like those around "google" and "prada," to see how they relate to the "space" topic.
To get started, simply head over to our documentation at pulsebit.lojenterprise.com/docs. You can easily copy, paste, and run the provided code in under 10 minutes. Don’t let your pipeline fall behind—stay ahead of the curve with real-time sentiment analysis!

Top comments (0)