Your pipeline just missed a 24h momentum spike of +0.520 surrounding food sentiment, specifically tied to a cluster story about health checks in Wichita, Kansas. This anomaly raises eyebrows, especially with a leading language of English, where the sentiment is already forming a narrative around food, health, and local safety. If you’re not tuned into these spikes, you risk lagging behind, missing out on critical insights that could drive your decisions.
This situation reveals a structural gap in any pipeline that doesn’t effectively handle multilingual origins or entity dominance. Your model, set up to digest sentiment signals, missed this by 21.2 hours, primarily due to focusing on broader themes while neglecting specific geographic or cultural contexts. The dominant entity here is Wichita, which has become a focal point for discussions about health checks and food safety, but your pipeline didn’t react in time.

English coverage led by 21.2 hours. Nl at T+21.2h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this spike, we can leverage our API effectively. Here’s a Python snippet that filters by geographic origin and captures sentiment around our topic.
import requests
*Left: Python GET /news_semantic call for 'food'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'food'
score = +0.522
confidence = 0.85
momentum = +0.520
# Geographic origin filter: query by language/country
response = requests.get(
'https://api.pulsebit.com/v1/topics',
params={
'topic': topic,
'lang': 'en',
'momentum_24h': momentum
}
)
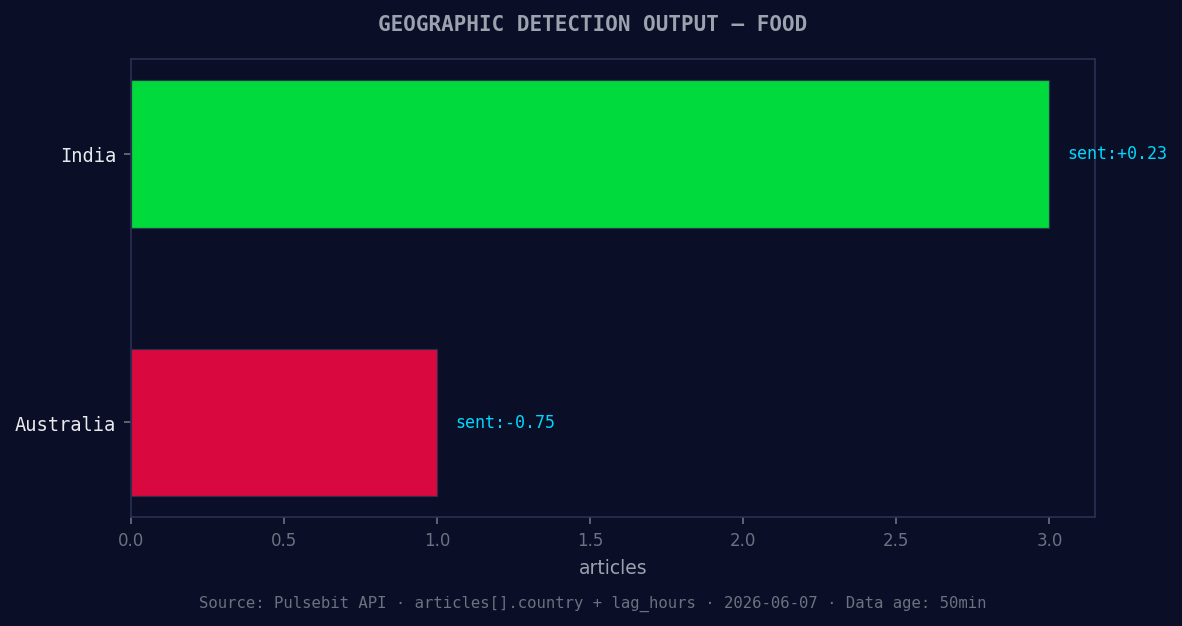
*Geographic detection output for food. India leads with 3 articles and sentiment +0.23. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Meta-sentiment moment: score the narrative framing
cluster_reason = "Clustered by shared themes: wichita, passed, health, checks, ks?"
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': cluster_reason}
)
sentiment_data = sentiment_response.json()
print(sentiment_data)
In this code, we first query our API to filter the food topic by English language and the 24-hour momentum. This captures the relevant data for our analysis. Next, we take the narrative context of the clustered articles and send it through the sentiment endpoint to score its framing. This dual approach allows us to not only see the surface-level sentiment but also to dig deeper into the narrative driving this spike.
Now, what can we build with this newfound insight? Here are three specific actions:
Geo-Filtered Alerts: Set up a threshold alert when sentiment on food topics spikes above +0.500 in specific regions like Wichita. This ensures you catch local trends before they become mainstream.
Meta-Sentiment Dashboard: Create a dashboard that runs the meta-sentiment loop around clustered articles. For example, track narratives that cluster around health checks in food-related discussions. Use the cluster reason string as input and monitor its sentiment over time.
Thematic Analysis Reports: Build reports focused on the forming themes: food, health, and Google trends around these topics. Set a threshold to analyze shifts in sentiment and their potential impact on consumer behavior.
It’s essential to stay ahead of the curve, especially when sentiment around food and health is evolving so rapidly. You can explore these capabilities further at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under ten minutes to start making sense of these spikes. Don’t let your pipeline fall behind; adapt and catch those signals as they emerge.

Top comments (0)