Your Pipeline Is 29.0h Behind: Catching Governance Sentiment Leads with Pulsebit
We just discovered a remarkable 24-hour momentum spike of +0.252 in governance sentiment, specifically driven by French press coverage. This anomaly indicates a significant shift in the narrative, led by a 29.0-hour lag in coverage compared to German sources. The urgency here is not just in the numbers; it's about understanding how these trends develop and the implications they have for our models.
The Problem
When your pipeline doesn’t account for multilingual origins or the dominance of certain entities, you risk missing critical insights. In this case, your model missed the governance sentiment spike by 29 hours, which is substantial. The leading language was French, highlighting a crucial gap where English-centric models fail to capture emerging narratives in other languages. This oversight could lead you to overlook significant shifts in sentiment that are brewing across different media landscapes.

French coverage led by 29.0 hours. German at T+29.0h. Confidence scores: French 0.85, English 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum spike, we can leverage our API effectively. Here’s how you can do it in Python:
import requests
# Geographic origin filter: query by language/country
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "governance",
"lang": "fr" # Filtering for French language articles
}
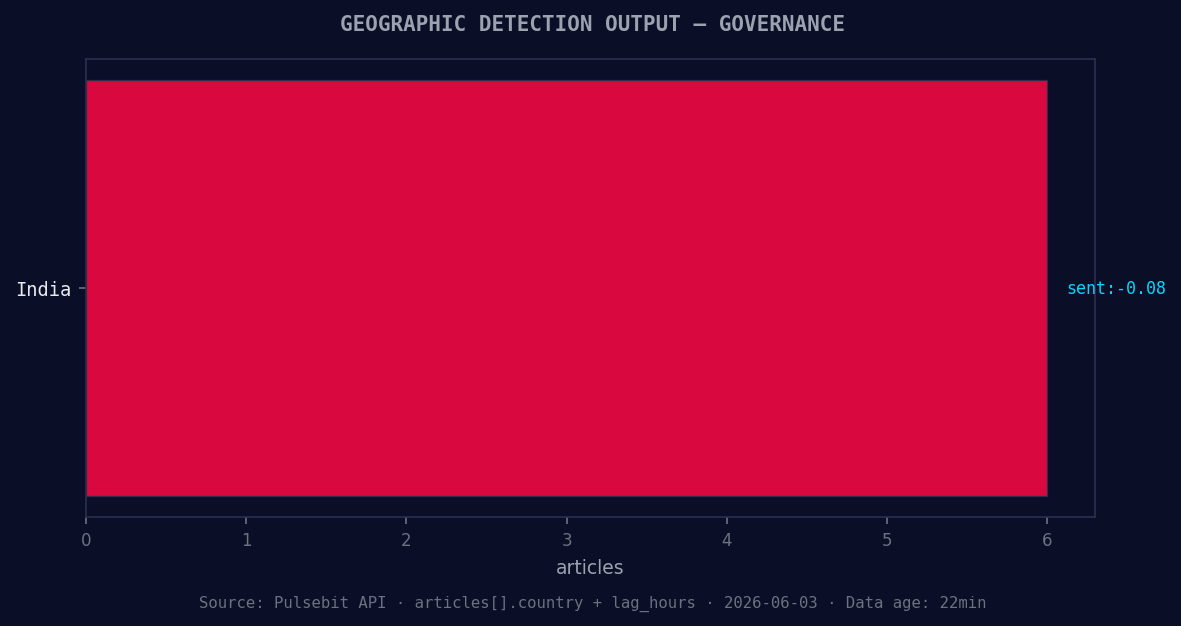
*Geographic detection output for governance. India leads with 6 articles and sentiment -0.08. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Output the relevant data
print(data)
Next, we’ll run the narrative framing through our sentiment analysis to evaluate its impact:
# Meta-sentiment moment
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_input = "Clustered by shared themes: africa, urged, strengthen, governance, reforms."
meta_payload = {
"text": meta_input
}
meta_response = requests.post(meta_sentiment_url, json=meta_payload)
meta_data = meta_response.json()
# Output the meta sentiment data
print(meta_data)
These two API calls allow us to filter for relevant articles and then evaluate the sentiment around the narrative, which is crucial for understanding the broader context.

Left: Python GET /news_semantic call for 'governance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Three Builds Tonight
Now that we’ve identified this key sentiment spike, let's explore three specific things we can build with this pattern:
Geographic Alert System: Set a threshold to alert when governance sentiment spikes above +0.250 from French sources. This can be implemented using the geo filter we demonstrated earlier. It ensures you stay ahead of emerging narratives in non-English speaking regions.
Narrative Strength Evaluator: Create a module that uses the meta-sentiment loop to score the framing of key narratives. Focus on the clustered themes like governance and Africa. For this, use the sentiment output from the meta-sentiment API call to adjust your model's weight on articles mentioning these themes.
Comparative Sentiment Dashboard: Build a dashboard that visually compares sentiment scores across languages and time zones. Use the +0.00 forming themes like governance, Google, and Africa against mainstream narratives. This will help in identifying lagging and leading sentiments effectively.
Get Started
You can find more details on how to implement these ideas at pulsebit.lojenterprise.com/docs. With this structured approach, you should be able to copy-paste and run this in under 10 minutes. This is your chance to leverage multilingual sentiment dynamics and stay ahead of the curve.

Top comments (0)