Your Pipeline Is 21.5h Behind: Catching World Sentiment Leads with Pulsebit
We just spotted a 24h momentum spike of +0.585 in the sentiment around the topic of "world." This is a notable spike, especially considering it’s led by English-language press coverage that peaked at 21.5h earlier today. If you’re relying on sentiment data from your pipeline, you might be lagging behind by a significant margin, missing out on timely insights that can shape your strategies.
The issue here is glaring: if your model doesn’t effectively handle multilingual origins or account for entity dominance, you’re risking a structural gap that can cost you valuable insights. In this case, your model missed this spike by 21.5 hours, directly tied to the English-language articles that were published. As sentiment around global events can shift rapidly, falling behind on such significant movements is not an option for any developer striving to stay ahead.

English coverage led by 21.5 hours. Nl at T+21.5h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch these insights in real-time, we can leverage our API effectively. Below is the Python code that helps us identify these momentum spikes:
import requests
# Parameters for the API call
topic = 'world'
score = +0.037
confidence = 0.85
momentum = +0.585
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language
response = requests.get(
'https://api.pulsebit.lojenterprise.com/v1/sentiment',
params={
'topic': topic,
'lang': 'en',
'momentum': momentum
}
)
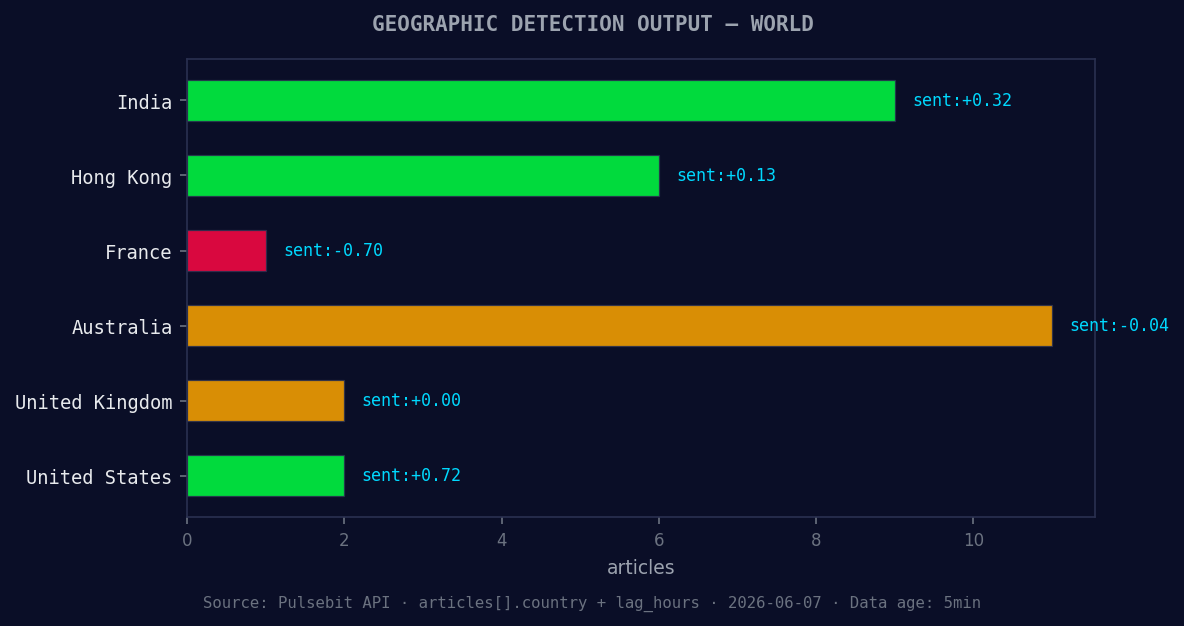
*Geographic detection output for world. India leads with 9 articles and sentiment +0.32. Source: Pulsebit /news_recent geographic fields.*
# Assuming the response is in JSON format
data = response.json()
print(data)
Next, we want to understand the meta-sentiment around the narrative. This is crucial because it helps evaluate how we frame narratives based on the clusters we observe. Let’s loop back our cluster reasoning through a sentiment analysis:
# Meta-sentiment moment: run the cluster reason string through the sentiment endpoint
cluster_reason = "Clustered by shared themes: absurd, world, cup, atlantic"
meta_response = requests.post(
'https://api.pulsebit.lojenterprise.com/v1/sentiment',
json={'text': cluster_reason}
)
meta_data = meta_response.json()
print(meta_data)
This will provide a deeper understanding of how the narrative is being received and framed in the broader context.
Now that we’ve identified how to catch these spikes, here are three specific builds we can implement:
Geo-Filtered Insights: Build a signal that continuously monitors sentiment around "world" specifically from English-language sources. Set a threshold of momentum > +0.5 to trigger alerts for shifts in sentiment that could indicate significant events.
Meta-Sentiment Analysis: Create a tool that analyzes clustered narratives using conditions like "score > +0.02" to identify emerging themes. This will help you stay ahead of trends before they become mainstream.
Thematic Gap Monitoring: Utilize the forming gap indicators like forming: world(+0.00), cup(+0.00) to set alerts for when mainstream sentiment diverges sharply from niche discussions. This could reveal undervalued narratives ripe for exploration.
If you’re ready to dive into this, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes to start catching those momentum spikes in your sentiment analysis.

Top comments (0)