Your Pipeline Is 29.1h Behind: Catching Innovation Sentiment Leads with Pulsebit
We recently stumbled upon a fascinating data anomaly: a sentiment score of +0.85 and a momentum of +0.00, with a leading language of English clocking in at 29.1 hours. This discrepancy is particularly critical when we consider the singular cluster story: "Separate ELEVATE track for Beyond Bengaluru startups welcomed." This insight suggests we might be missing a significant innovation trend that demands our immediate attention.
The Problem
This data reveals a structural gap in any pipeline that isn't equipped to handle multilingual origins or entity dominance. If your models aren't capturing these nuances, you might have missed this opportunity by a staggering 29.1 hours. The leading English sentiment surrounding innovation is being overshadowed by the more mainstream themes of elevate, track, and beyond, which can lead to a skewed understanding of emergent trends. How much are you losing out on by not integrating this kind of nuanced analysis into your sentiment tracking?

English coverage led by 29.1 hours. Nl at T+29.1h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
Here’s how to catch this anomaly using our API. First, let’s filter for the English language:
import requests
*Left: Python GET /news_semantic call for 'innovation'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "innovation",
"score": +0.850,
"confidence": 0.85,
"momentum": +0.000,
"lang": "en" # Geographic origin filter
}
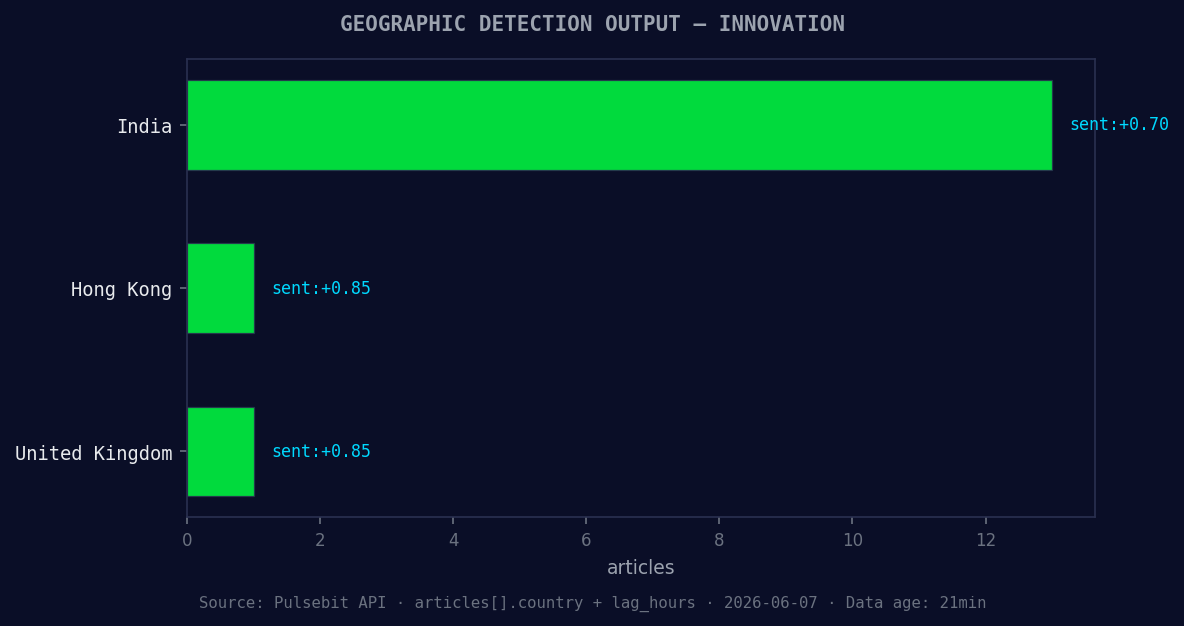
*Geographic detection output for innovation. India leads with 13 articles and sentiment +0.70. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
Next, we’ll run the cluster reason string through our sentiment endpoint to score the narrative framing itself. This adds a unique layer to our insights:
meta_sentiment_url = "https://api.pulsebit.com/sentiment"
meta_input = "Clustered by shared themes: elevate, track, beyond, bengaluru, startups."
meta_response = requests.post(meta_sentiment_url, json={"text": meta_input})
meta_data = meta_response.json()
print(meta_data)
This process allows us to gauge how the overarching narrative fits into the current sentiment landscape, providing a richer context for our findings.
Three Builds Tonight
With this pattern, we can tackle three specific builds that can help us capture this sentiment:
Geographic Opportunity Detection: Use the geographic origin filter to monitor not just the English sentiment but also other languages. Set a threshold for sentiment scores above +0.800 to catch emerging trends in different linguistic landscapes.
Meta-Sentiment Analysis: Create a feature that automatically runs any identified cluster reason strings through our sentiment scoring endpoint. Use this to analyze patterns around emerging themes like innovation, which currently sits at +0.00 momentum.
Dynamic Topic Radar: Build a radar that continuously monitors sentiment changes around specific keywords, such as "new" and "students." Set a signal threshold of +0.500 to trigger alerts when these themes start aligning with more mainstream topics like elevate and track.
Get Started
Dive into our API at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can replicate this analysis in under 10 minutes. Don't let your pipeline fall behind — leverage these insights to stay ahead of the curve.

Top comments (0)