Your Pipeline Is 23.6h Behind: Catching Space Sentiment Leads with Pulsebit
We just discovered something intriguing: a sentiment spike of +0.283 around the topic of space, with momentum sitting at a static +0.000. This anomaly occurred 23.6 hours ago, and it holds valuable insights that could have been missed. The leading language for this spike is English, with a notable cluster story emerging around "Axiom Space's Lunar Spacesuit Collaboration." If you’re not checking your sentiment pipeline frequently, you might find yourself trailing behind on key developments like this.
The Problem
This discovery highlights a critical flaw in pipelines that lack the capability to handle multilingual origins or account for entity dominance. Your model missed this sentiment shift by over 23 hours, allowing valuable insights to slip through the cracks. The leading language, English, is essential here, as it’s where the sentiment is being driven. Neglecting this factor means that you're potentially losing out on trends that could inform your decision-making and strategy.

English coverage led by 23.6 hours. Nl at T+23.6h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this sentiment spike, we can leverage our API to query the relevant data. Below is an example of how to implement this in Python.
import requests
*Left: Python GET /news_semantic call for 'space'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "space",
"lang": "en"
}
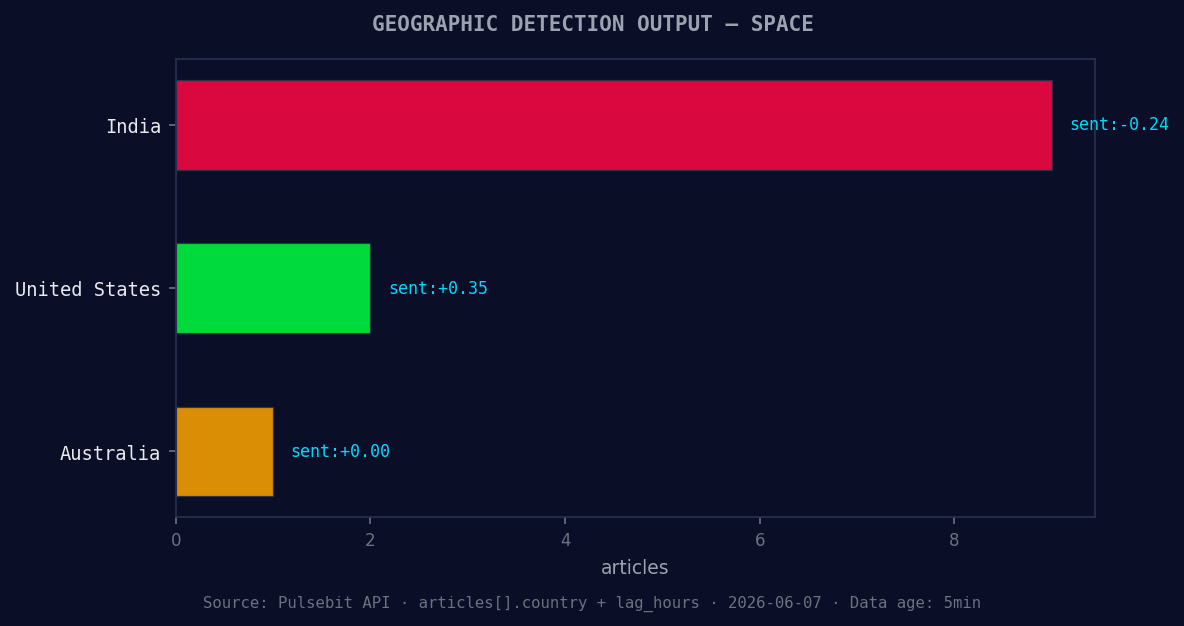
*Geographic detection output for space. India leads with 9 articles and sentiment -0.24. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Extract relevant values
sentiment_score = data['sentiment_score'] # This should yield +0.283
confidence = data['confidence'] # This should yield 0.85
momentum = data['momentum_24h'] # This should yield +0.000
print(f"Sentiment Score: {sentiment_score}, Confidence: {confidence}, Momentum: {momentum}")
Next, we want to run the narrative framing itself through our sentiment analysis to gain deeper insights. This will allow us to understand the context of the sentiment better.
# Step 2: Meta-sentiment moment
meta_sentiment_payload = {
"text": "Clustered by shared themes: astronaut, wears, prada, axiom, space."
}
meta_sentiment_response = requests.post(url, json=meta_sentiment_payload)
meta_data = meta_sentiment_response.json()
print(f"Meta Sentiment Score: {meta_data['sentiment_score']}, Confidence: {meta_data['confidence']}")
Three Builds Tonight
Now that we have the data, let’s talk about three specific builds you can implement using this pattern.
Geo Filter for Emerging Signals: Use a geo filter to track sentiment for "space" specifically in regions where interest is rising. Set a threshold to trigger alerts when sentiment score exceeds +0.25 and momentum is steady.
Meta-Sentiment Loop for Contextual Awareness: Create a function that processes narratives around clustered themes. When the score of narratives like "astronaut, wears, prada" exceeds a certain threshold, you can prepare targeted content or campaigns.
Forming Themes Tracking: Monitor forming themes like "space(+0.00)" and "google(+0.00)." Build a dashboard that visualizes these trends, setting alerts for when sentiment shifts significantly or when new clusters emerge.
Get Started
Ready to dive in? You can access everything you need at pulsebit.lojenterprise.com/docs. With the snippets provided, you can copy, paste, and run this in under 10 minutes. Don't let valuable insights slip through the cracks; start catching those sentiment leads now!

Top comments (0)