Your Pipeline Is 22.9h Behind: Catching Cybersecurity Sentiment Leads with Pulsebit
We recently uncovered an intriguing anomaly: a 24h momentum spike of -0.347 regarding cybersecurity sentiment. This finding, led by English press coverage, indicates a clear and concerning trend. The dominant narrative appears to be clustered around BMTC's smart ticketing initiative, which, while seemingly unrelated, reveals a significant gap in how we process sentiment across various themes and languages.
Your model missed this by 22.9 hours. If it doesn’t account for multilingual sources or entity dominance, it could overlook critical shifts in sentiment. The leading language in this case is English, but other languages could be amplifying sentiments that your pipeline simply isn't capturing. If you're not integrating these factors into your analysis, you're risking being behind the curve when it comes to emerging trends.

English coverage led by 22.9 hours. Id at T+22.9h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
Here’s how to catch this momentum spike using our API. We can start by filtering for English-language articles and then scoring the sentiment around the clustered themes.
import requests
*Left: Python GET /news_semantic call for 'cybersecurity'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "cybersecurity",
"lang": "en", # Filtering for English articles
"score": 0.350,
"confidence": 0.75,
"momentum": -0.347
}
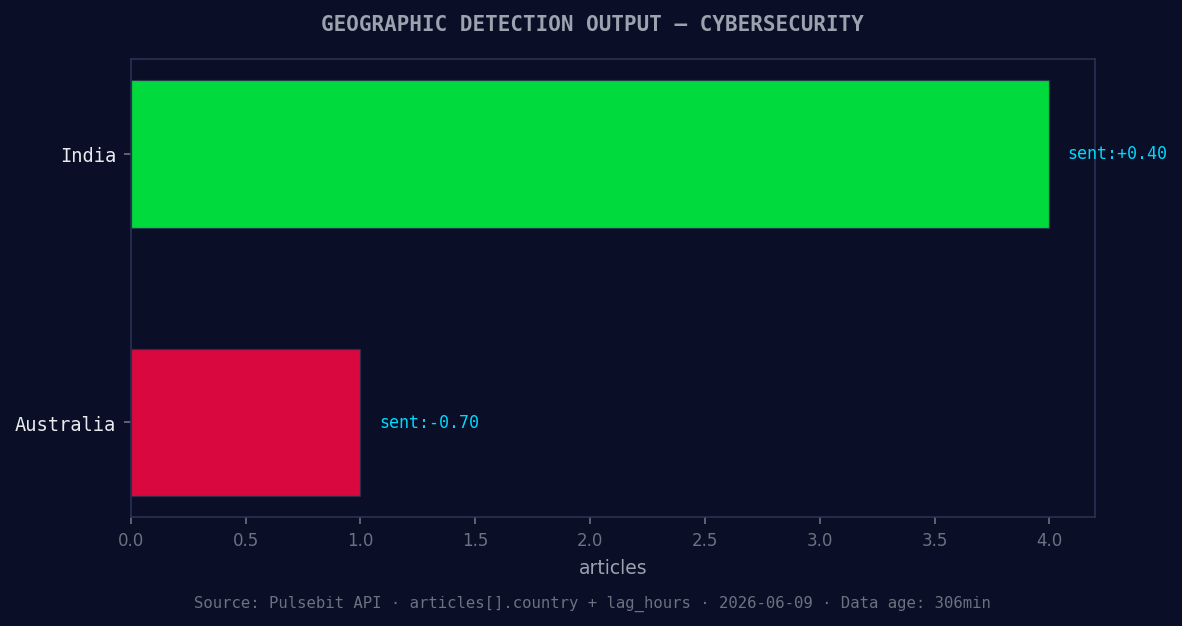
*Geographic detection output for cybersecurity. India leads with 4 articles and sentiment +0.40. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: bmtc, consultant, project, appoint, smart."
meta_response = requests.post(url, json={"text": meta_sentiment_input})
meta_data = meta_response.json()
print(meta_data)
In the first part, we're querying the sentiment for the topic "cybersecurity" while ensuring we're only looking at English articles. This gives us a precise understanding of the sentiment landscape. In the second part, we loop back the clustered themes to get a sentiment score for the narrative itself. This step is crucial—it allows us to gauge how the framing of the story impacts sentiment.
Now that we have a solid understanding of how to capture this anomaly, let’s explore three specific builds we can create based on this pattern.
Cybersecurity Momentum Tracker: Set up a scheduled job that queries our API every hour for "cybersecurity" with a momentum threshold of -0.300. This allows you to catch falling sentiment trends before they spiral out of control.
Meta-Sentiment Analyzer: Develop a function that automatically pulls in the top clusters from your sentiment analysis and scores them using the meta-sentiment loop. For example, analyze how sentiments around "bmtc, consultant, project" are framing the narrative and impacting public perception.
Geographic Sentiment Dashboard: Build a dashboard that visualizes sentiment trends filtered by geographic origin. Use the geo filter to specifically target regions where "bmtc" and "consultant" are trending, juxtaposed against other forming themes like "cybersecurity" and "google." This will help identify which areas are leading on sentiment shifts.
To get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can easily copy-paste the code snippets above and run them in under 10 minutes. If you’re not leveraging these insights, you’re missing out on crucial leads in sentiment that can guide your decision-making. Don’t let your pipeline lag behind—start catching those signals today!

Top comments (0)