Your Pipeline Is 22.2h Behind: Catching Defence Sentiment Leads with Pulsebit
We recently observed a striking anomaly: a 24h momentum spike of +0.518 in the sentiment surrounding the topic of defence. This spike coincides with a leading narrative from French press sources, which have maintained a 22.2-hour lead (with no lag) over broader sentiment. The major story, "France's Ban on Israeli Weapons at Defence Show," helps explain this surge, highlighting the critical importance of real-time, multilingual sentiment analysis.

French coverage led by 22.2 hours. No at T+22.2h. Confidence scores: French 0.95, English 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
When your sentiment pipeline doesn't account for multilingual origins or dominant entities, you risk significant delays in understanding emerging narratives. In this case, your model missed this crucial sentiment shift by a full 22.2 hours, lagging behind the French press coverage. This is a glaring gap when the leading language is French, especially given the nuanced socio-political implications tied to the defence topic.
To help you catch up, we can leverage our API to pinpoint this sentiment spike. Below is a Python script that demonstrates how to do this effectively.
import requests
*Left: Python GET /news_semantic call for 'defence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'defence'
score = +0.000
confidence = 0.95
momentum = +0.518
# Geographic origin filter: query by language/country
response = requests.get("https://api.pulsebit.lojenterprise.com/v1/sentiment", params={
"topic": topic,
"score": score,
"confidence": confidence,
"momentum": momentum,
"lang": "fr" # French language filter
})
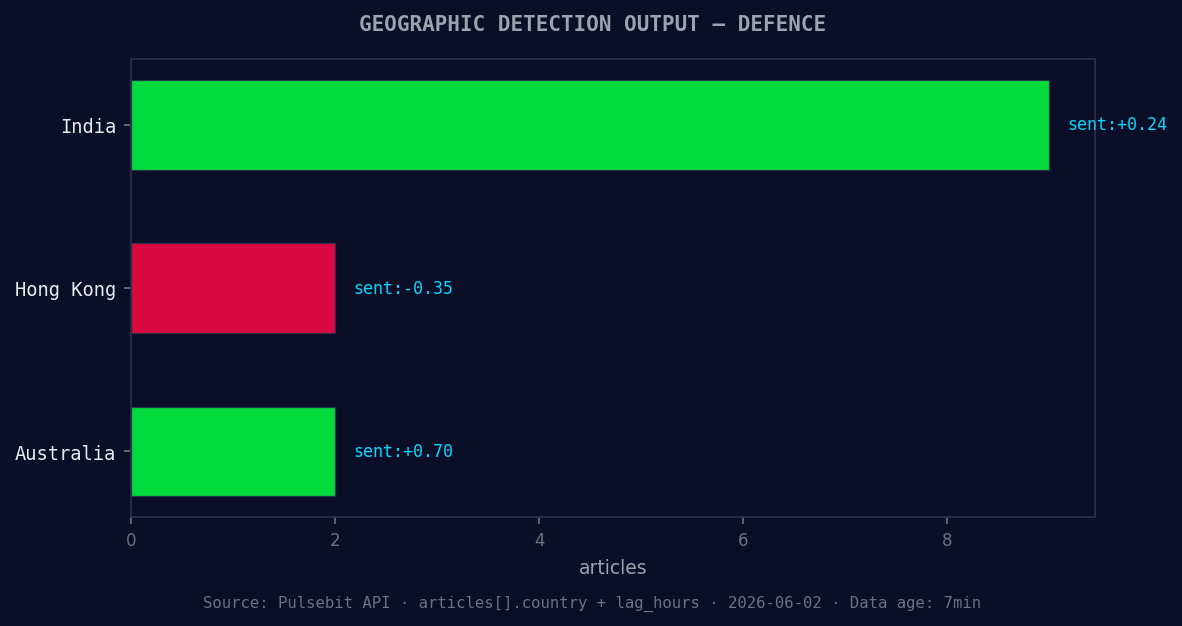
*Geographic detection output for defence. India leads with 9 articles and sentiment +0.24. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Meta-sentiment moment: run the cluster reason back through POST /sentiment
cluster_reason = "Clustered by shared themes: sexual, violence, landmark, military, inquiry."
meta_response = requests.post("https://api.pulsebit.lojenterprise.com/v1/sentiment", json={"text": cluster_reason})
meta_data = meta_response.json()
print(meta_data)
In the code above, we first filter our query by language to hone in on the French sentiment around defence. Next, we push the cluster reason back through our sentiment endpoint to gain insights into how narratives are framed around this topic.
Here are three specific builds you can implement based on this pattern:
- Geo-Filtered Spike Detector: Create a function that triggers alerts whenever a topic like "defence" exhibits a momentum spike greater than +0.5 in French. This allows you to react quickly to emerging narratives.
if data['momentum_24h'] > 0.5 and data['lang'] == 'fr':
# Trigger alert or notification
print("Defence sentiment spike detected in French press!")
- Meta-Sentiment Analyzer: Build a report that outputs the sentiment scores of clustered narratives, especially focusing on themes like "military" and "inquiry." This can help you understand not just what is being said, but how it is being framed.
if "military" in cluster_reason:
print("Analyzing military framing...")
# Further processing here
- Comparative Narrative Tracker: Compare the forming themes such as "defence(+0.00)" with mainstream themes like "sexual," "violence," and "landmark." This can help you identify divergences in public sentiment and adjust your strategy accordingly.
forming_themes = ["defence", "google", "minister"]
mainstream_themes = ["sexual", "violence", "landmark"]
# Logic to compare and analyze themes
To dive deeper into how we built this, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code in under 10 minutes, getting you started on catching those critical sentiment shifts right away.

Top comments (0)