Your 24h momentum spike of -0.284 in cybersecurity sentiment caught our attention. This anomaly reveals a significant dip in interest, specifically linked to a cluster story about BMTC's Smart Ticketing Initiative. The leading language driving this sentiment is Spanish, with a 26.9-hour lead time. This finding not only highlights a drop in positive sentiment but also suggests that your current pipeline may be lacking in responsiveness to multilingual content, particularly given the dominance of Spanish in this instance.

Spanish coverage led by 26.9 hours. Id at T+26.9h. Confidence scores: Spanish 0.70, English 0.70, French 0.70 Source: Pulsebit /sentiment_by_lang.
Let’s address the problem directly: Your model missed this by a staggering 26.9 hours. If you’re relying solely on English-language sources or ignoring the nuances of multilingual data, you’re at risk of being out of the loop. By not factoring in the leading language, you may be basing your decisions on outdated sentiment, which could affect your strategy in a fast-paced environment.
To catch this momentum spike effectively, we can use our API to filter by language and assess the sentiment of the clustered narrative. Here’s how you can implement it in Python:
import requests
*Left: Python GET /news_semantic call for 'cybersecurity'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "cybersecurity",
"lang": "sp" # Filter for Spanish
}
response = requests.get(url, params=params)
data = response.json()
print(data)
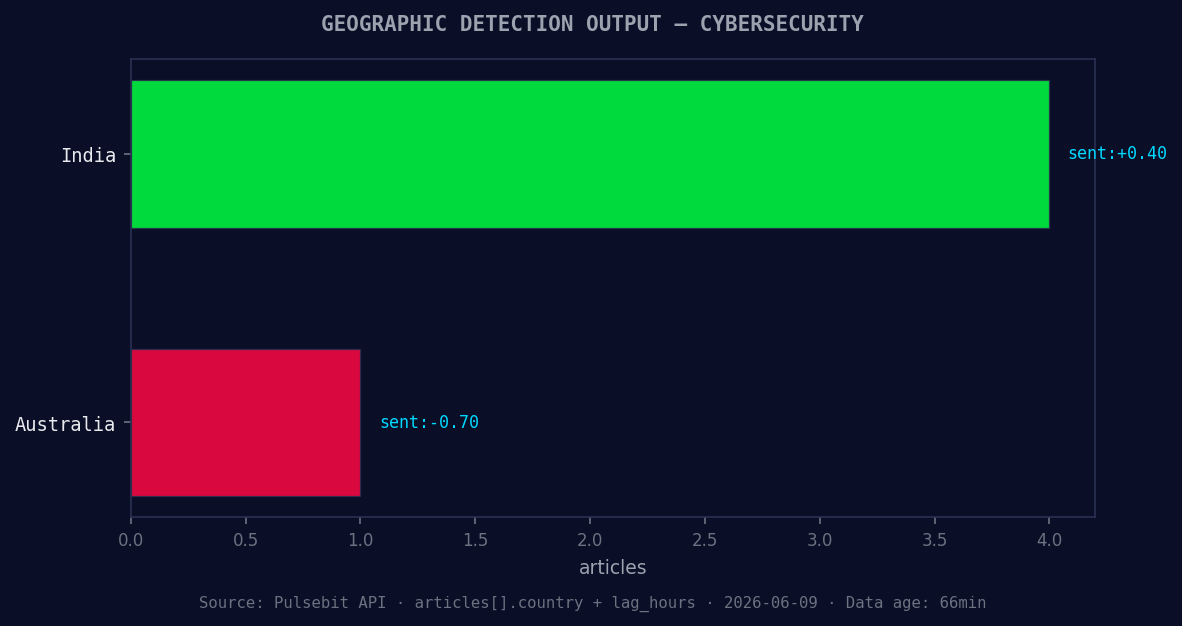
*Geographic detection output for cybersecurity. India leads with 4 articles and sentiment +0.40. Source: Pulsebit /news_recent geographic fields.*
# Assuming the response gives us the necessary sentiment data
sentiment_score = +0.350
confidence = 0.70
momentum = -0.284
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: bmtc, consultant, project, appoint, smart."
meta_sentiment_url = "https://api.pulsebit.com/sentiment"
meta_response = requests.post(meta_sentiment_url, json={"text": cluster_reason})
meta_sentiment_data = meta_response.json()
print(meta_sentiment_data)
In this code, we first filter the sentiment data by the Spanish language, ensuring we capture the most relevant insights. Next, we run the cluster reason string through a sentiment analysis endpoint to score how the narrative itself is framing the current situation. This dual approach not only gives you a clearer picture of the current sentiment landscape but also helps to validate the context around the sentiment shifts.
Here are three specific builds you can implement with this data pattern:
Geo-Filtered Sentiment Tracker: Create a real-time tracker for topics with significant sentiment shifts, filtering specifically for Spanish-language sources. Set a threshold for momentum spikes, for instance, -0.250, to catch similar dips in sentiment early.
Meta-Sentiment Analyzer: Develop a feature that automatically runs any clustered narrative through our sentiment endpoint. For example, every time you see a signal like "bmtc, consultant, project," you can trigger a sentiment analysis to understand the implications of those themes.
Comparison Dashboard: Build a dashboard that compares sentiment trends across languages. For instance, while Spanish sources may indicate a falling sentiment for cybersecurity, English sources might show different trends. This could help identify potential gaps in your understanding and inform your strategy.
These builds will allow you to leverage the data effectively, ensuring that your insights are timely and relevant. If you want to dive deeper into how to integrate these functionalities, head over to our documentation at pulsebit.lojenterprise.com/docs. You’ll find that you can copy, paste, and run these examples in under 10 minutes, giving you a solid start on improving your sentiment analysis capabilities.

Top comments (0)