Your Pipeline Is 14.2h Behind: Catching Health Sentiment Leads with Pulsebit
We recently observed a fascinating anomaly: a 24h momentum spike of +0.800 in health sentiment. This spike caught our attention, particularly as it followed a narrative clustered around the NFHS-6 data, which combines themes of joy and pain in the health sector. With a leading language of English, this sentiment shift indicates a significant trend that may have escaped your current pipeline, especially if it doesn't account for multilingual origins or dominant entities.

English coverage led by 14.2 hours. No at T+14.2h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
The Problem
This spike reveals a critical structural gap in any sentiment analysis pipeline that doesn't handle variations in language or the dominance of specific entities. In this case, if your model isn't tuned to recognize the urgency of the English press, you might have missed this insight by a staggering 14.2 hours. That’s a long time when it comes to making timely decisions based on health sentiment. If your pipeline is still relying on a single-language approach or failing to account for key entities in your analysis, you’re likely lagging behind on crucial data.
The Code
To start catching these insights, we can leverage our API to filter for English-language content and analyze the sentiment around the clustered narrative. Below is the Python code snippet to get you started:
import requests
*Left: Python GET /news_semantic call for 'health'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.io/v1/sentiment"
params = {
"topic": "health",
"lang": "en"
}
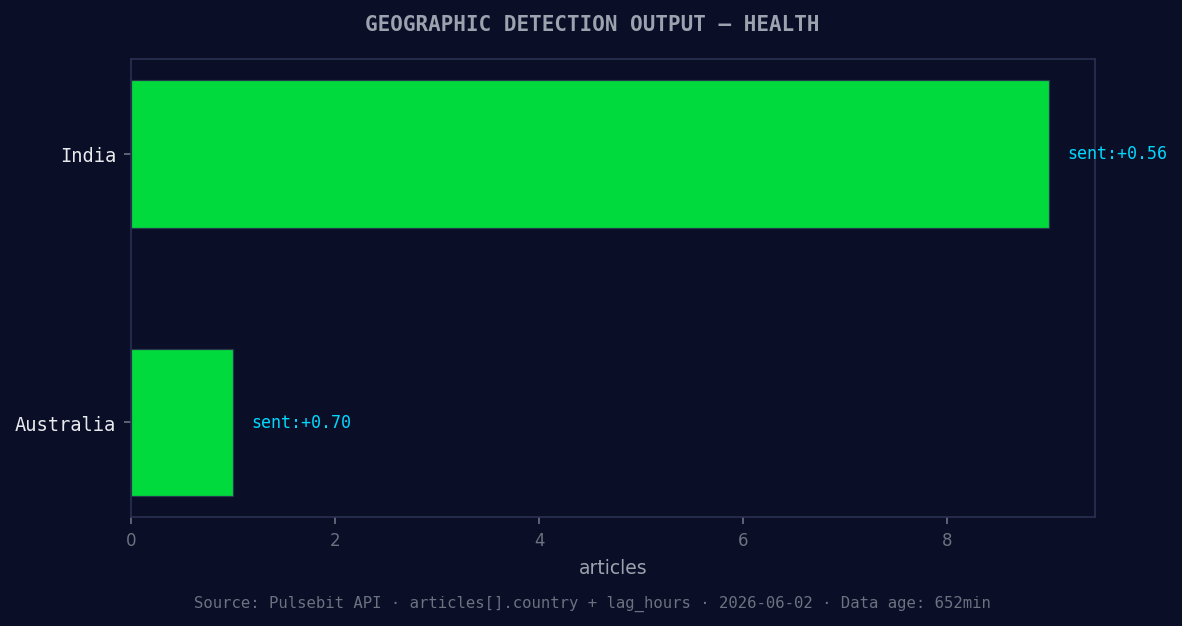
*Geographic detection output for health. India leads with 9 articles and sentiment +0.56. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Extract sentiment score and momentum
sentiment_score = data['sentiment_score'] # +0.177
momentum = data['momentum_24h'] # +0.800
confidence = data['confidence'] # 0.750
print(f"Sentiment Score: {sentiment_score}, Momentum: {momentum}, Confidence: {confidence}")
# Step 2: Meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: nfhs-6, joy, pain:, data, health."
meta_response = requests.post(url, json={"text": meta_sentiment_input})
meta_data = meta_response.json()
print("Meta Sentiment Analysis:", meta_data)
By filtering for English-language articles, we can ensure we’re capturing the most relevant insights. Then, we loop back through the narrative string to score its sentiment, allowing us to evaluate how the themes of joy and pain are framed in relation to the NFHS-6 data.
Three Builds Tonight
Here are three specific builds you can implement using the patterns we just uncovered:
- Health Sentiment Signal: Set a threshold where you trigger alerts for any momentum spikes above +0.500 in sentiment around the topic of health. This ensures you’re always in tune with significant shifts.
if momentum > 0.500:
print("Alert: Significant health sentiment spike detected!")
- Geographic Origin Filter: Expand your analysis to include healthcare-related topics, ensuring you filter for articles from English-speaking countries. This gives you a focused lens on regional health trends.
params = {
"topic": "healthcare",
"lang": "en"
}
- Meta-Sentiment Loop: Use the meta-sentiment analysis to create a dashboard that visualizes how narratives shift over time concerning healthcare. Track sentiments around keywords like "joy" and "pain" to see how public perception evolves.
keywords = ["joy", "pain"]
for keyword in keywords:
# Code to fetch and analyze sentiments for these keywords
Get Started
Ready to dive in? You can find everything you need to get started at pulsebit.lojenterprise.com/docs. We believe you’ll be able to copy-paste and run this in under 10 minutes, and that’s the kind of efficiency we’re excited about.

Top comments (0)