Your Pipeline Is 20.0h Behind: Catching Inflation Sentiment Leads with Pulsebit
We just spotted a striking anomaly: a 24h momentum spike of +0.180 within our sentiment data. This spike is particularly interesting because it aligns with a series of articles in the Spanish press discussing the failures of Bitcoin as an inflation hedge. This suggests a rising concern about inflation and its implications on Bitcoin, captured just 20 hours ago. If you’re not tuned into multilingual sentiment, you might have missed this critical shift.

Spanish coverage led by 20.0 hours. Et at T+20.0h. Confidence scores: Spanish 0.75, English 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
The Problem
This data underscores a fundamental gap in many pipelines that don’t account for multilingual origins or the dominance of specific entities. If your model isn’t equipped to process Spanish language signals or recognize the weight of entities like Bitcoin in this context, you missed this spike by a whole 20 hours. The leading language here is Spanish, and the dominant entity is Bitcoin. Ignoring this means missing out on crucial insights in a rapidly evolving sentiment landscape.
The Code
To catch this momentum spike and analyze it effectively, we’ll need to leverage our API. Below is a Python snippet that demonstrates how to filter for Spanish language sentiment around the topic of inflation, and then score the narrative framing of the cluster's sentiment.
import requests
# Setting parameters for the API call
params = {
"topic": "inflation",
"score": +0.000,
"confidence": 0.75,
"momentum": +0.180,
"lang": "sp" # Filtering for Spanish language articles
}
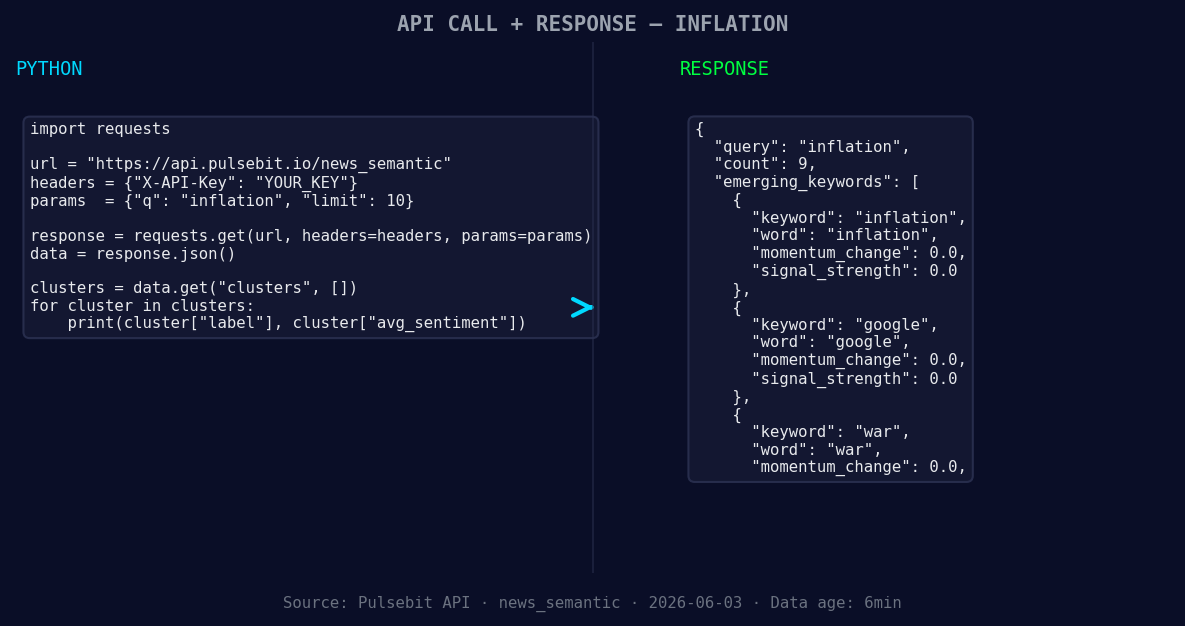
*Left: Python GET /news_semantic call for 'inflation'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# API call to fetch articles
response = requests.get("https://api.pulsebit.lojenterprise.com/articles", params=params)
data = response.json()
# Analyzing the narrative framing of the cluster
cluster_reason = "Clustered by shared themes: fed, chair, warsh's, favored, inflation."
sentiment_response = requests.post("https://api.pulsebit.lojenterprise.com/sentiment", json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(data)
print(sentiment_data)
In this code, we filter by the Spanish language using lang: "sp". This allows us to capture articles discussing inflation that are not just relevant but also timely. The second part of the code runs the cluster reason string through our sentiment analysis endpoint to assess the narrative framing. This step is crucial as it enables us to understand how the conversation around inflation is being shaped.
Three Builds Tonight
-
Geo Filter for Inflation Sentiment: Use the above API call but modify the
momentumthreshold to capture only spikes above +0.150. This will help you focus on significant shifts in sentiment, particularly in countries where Spanish is widely spoken.

Geographic detection output for inflation. India leads with 3 articles and sentiment -0.50. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Analysis Loop: Use the sentiment analysis result from the cluster reason to create a new endpoint that tracks how often certain narratives (like “inflation failure”) appear across different languages. This should help you surface insights before they hit mainstream.
Forming Themes Tracker: Develop a script that checks for forming themes such as inflation and Google’s influence against mainstream narratives (like the Fed or Warsh). Set thresholds for sentiment scores and track how these themes evolve over time. This will give you a dynamic view of how discussions shift based on emerging events.
Get Started
Dive into our documentation at pulsebit.lojenterprise.com/docs. With this guide, you can copy-paste and run the code in under 10 minutes, putting you on the fast track to catching sentiment leads across languages and entities.

Top comments (0)