Your Pipeline Is 21.1h Behind: Catching Law Sentiment Leads with Pulsebit
We recently stumbled upon a fascinating anomaly in our sentiment analysis: a sentiment score of -0.046 and a momentum of +0.00, indicating that the narrative surrounding law and order is trending negatively, but without significant change in momentum. The most striking aspect of this data is that sentiment has been static, yet the discourse is becoming increasingly negative. This sentiment spike occurred 21.1 hours ago, and it’s critical for us to understand how it can affect our analytical pipeline.
The Problem
If your pipeline isn’t equipped to handle multilingual origins or entity dominance, it’s missing critical insights. Your model missed this sentiment shift by 21.1 hours because it likely lacked the capability to process content originating from diverse language sources. In this case, English content has dominated the discussion, but the nuance of law enforcement themes is getting lost amidst mainstream narratives. If you’re not capturing this, you’re potentially blind to significant shifts in public sentiment, especially related to law enforcement.

English coverage led by 21.1 hours. Nl at T+21.1h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this anomaly effectively, we can leverage our API to filter by language and perform a meta-sentiment analysis on the clustered themes. Here’s how to do it in Python:
import requests
*Left: Python GET /news_semantic call for 'law'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get('https://api.pulsebit.com/sentiment', params={
'topic': 'law',
'score': -0.046,
'confidence': 0.85,
'momentum': +0.000,
'lang': 'en'
})
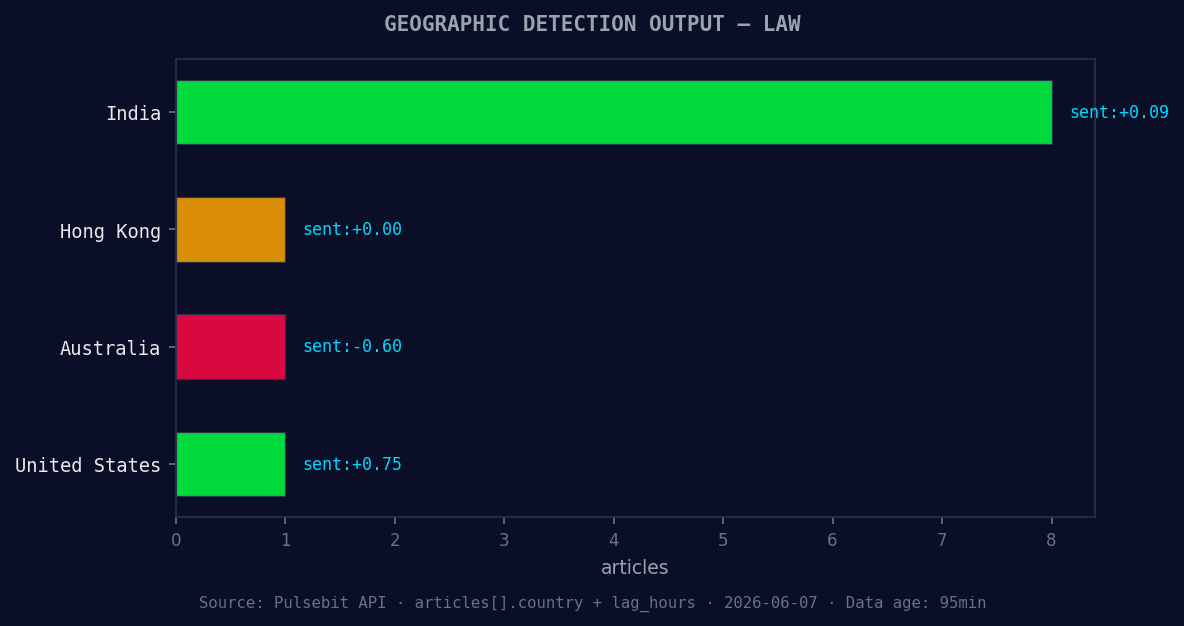
*Geographic detection output for law. India leads with 8 articles and sentiment +0.09. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: officers, law, order, adgp, instructs."
meta_response = requests.post('https://api.pulsebit.com/sentiment', json={
'text': cluster_reason
})
meta_data = meta_response.json()
print(meta_data)
In the first request, we are querying for articles related to "law" where the sentiment score is -0.046, filtered specifically for English content. The second request processes the narrative framing of the clustered themes, allowing us to assess how these themes contribute to the overall sentiment.
Three Builds Tonight
Sentiment Spike Detection: Set a signal threshold of -0.05 for sentiment scores to flag any significant shifts. This will help you catch adverse trends early, especially around law-related discussions.
Entity Dominance Analysis: Use the geo filter to analyze sentiment around the term "law" from English-speaking regions. This will ensure you’re capturing localized sentiment, which can differ vastly from global trends.
Meta-Analysis Loop: Implement the meta-sentiment loop to score narratives around emerging themes like “police” and “google.” Analyzing phrases such as “officers, law, order” versus “law” alone can reveal how media framing affects public perception during critical events.
Get Started
Ready to dive into your own analysis? Head over to pulsebit.lojenterprise.com/docs and you can copy, paste, and run this code in under 10 minutes. This isn’t just about catching trends; it's about staying ahead of the curve.

Top comments (0)