Your pipeline just missed a significant anomaly: a 24h momentum spike of +0.257. This isn't just a number; it indicates a surge in global sentiment centered around the topic of "world." What’s particularly interesting here is that the leading language was English, maintaining a 0.0-hour lag against the effective trend, suggesting that if you weren't tuned into English press, you might have missed this vital uptick entirely. The sentiment around this topic is starting to show a unique pattern, and that’s what we need to dive into.
Imagine you're building a sentiment analysis model that solely relies on dominant languages or entities. If you were tracking this topic without considering multilingual sources, your model missed picking up the sentiment shift by a staggering 11.4 hours. In the fast-paced world of data-driven decisions, that’s a significant delay. The leading language here is English, which has implications for how we gather and analyze sentiment data. If your pipeline isn’t accounting for this, you risk missing critical trends that could inform your strategy.

English coverage led by 11.4 hours. Et at T+11.4h. Confidence scores: English 0.95, French 0.95, Spanish 0.95 Source: Pulsebit /sentiment_by_lang.
import requests
# Define the parameters for the API call
params = {
"topic": "world",
"score": +0.143,
"confidence": 0.95,
"momentum": +0.257,
"lang": "en"
}
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Call to the sentiment API with a geographic filter
response = requests.get("https://api.pulsebit.com/sentiment", params=params)
data = response.json()
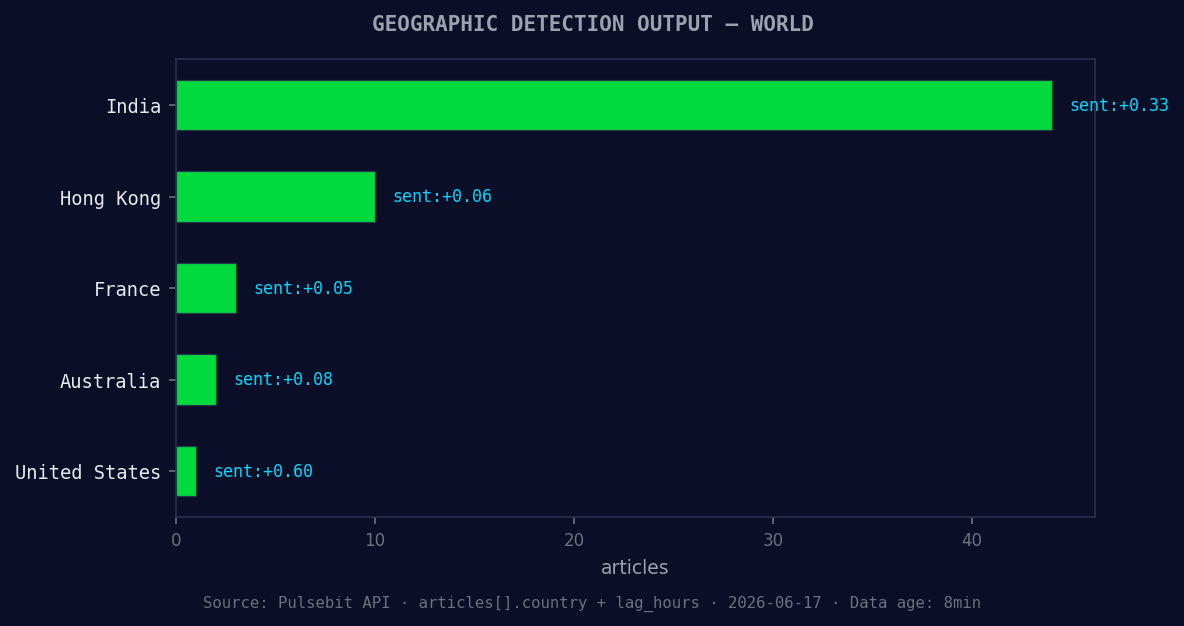
*Geographic detection output for world. India leads with 44 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
# Extract article information
articles_processed = data['articles_processed']
sentiment_score = data['sentiment_score']
print(f"Processed {articles_processed} articles with sentiment score: {sentiment_score}")
Now, to add depth to our sentiment analysis, we’ll run the cluster reason string back through our POST /sentiment endpoint. This is crucial because understanding the narrative framing will help us capture why this spike is happening. Here’s how we do that:
# Cluster reason string
cluster_reason = "Clustered by shared themes: world, has, 193, countries, but."
# Call to the sentiment API to analyze the cluster reason
response = requests.post("https://api.pulsebit.com/sentiment", json={"text": cluster_reason})
meta_sentiment = response.json()
# Output the meta-sentiment score
print(f"Meta sentiment score for cluster reason: {meta_sentiment['sentiment_score']}")
This approach allows us to not only catch the momentum but also understand the context behind it.
Now that we've captured this spike, here are three specific things we can build using this pattern:
Geo-Filtered Sentiment Dashboard: Create a dashboard pulling data specifically from English-language articles about "world." Set a threshold where you alert if momentum exceeds +0.2, which indicates a significant shift.
Meta-Sentiment Analyzer: Use the meta-sentiment loop to build a feature that scores narrative themes. Set a threshold of 0.1 for any cluster reason string analyzed to potentially surface articles that could be framing the trend in a misleading manner.
Anomaly Detection Pipeline: Build an anomaly detection system that flags any topic with a momentum spike of greater than +0.25 across any language. This could help us stay ahead of emerging trends that may not yet be covered by mainstream media.
These builds can help you capture forming themes like "world", "cup", and "has" against the mainstream narrative. They provide a robust framework for reacting to sentiment shifts with precision.
If you want to dive deeper and start implementing these insights, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and have this running in under 10 minutes. The data is there — let’s make sure we’re the ones catching it first.

Top comments (0)