Your Pipeline Is 21.0h Behind: Catching Artificial Intelligence Sentiment Leads with Pulsebit
We just encountered a fascinating anomaly: a 24-hour momentum spike of -1.350 in the realm of artificial intelligence. This spike, driven by two key articles clustered around the themes of "AI Firms and Manhattan Office Space," raises some serious questions about the timeliness of our sentiment analysis pipelines. The leading language for this narrative is English, with a lag of 21.0 hours behind the sentiment shift. This discovery could very well highlight a crucial gap in our analytical workflows.
If your pipeline isn't equipped to handle multilingual origins or entity dominance, you're missing out on significant sentiment shifts like this one by a staggering 21 hours. A spike like -1.350 indicates that while AI-related discussions are growing, the mainstream narrative is still focused on how, jobs, and India. If you're exclusively monitoring a single language or dominant entity, you're not just a bit behind; you're potentially missing entire trends as they develop.

English coverage led by 21.0 hours. Sw at T+21.0h. Confidence scores: English 0.85, Spanish 0.85, Sv 0.85 Source: Pulsebit /sentiment_by_lang.
Let's dig into the code that caught this anomaly. We can leverage our API to identify sentiment shifts around artificial intelligence. Here’s how we can do that:
import requests
*Left: Python GET /news_semantic call for 'artificial intelligence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter for English
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "artificial intelligence",
"score": +0.850,
"confidence": 0.85,
"momentum": -1.350,
"lang": "en" # Filter by language
}
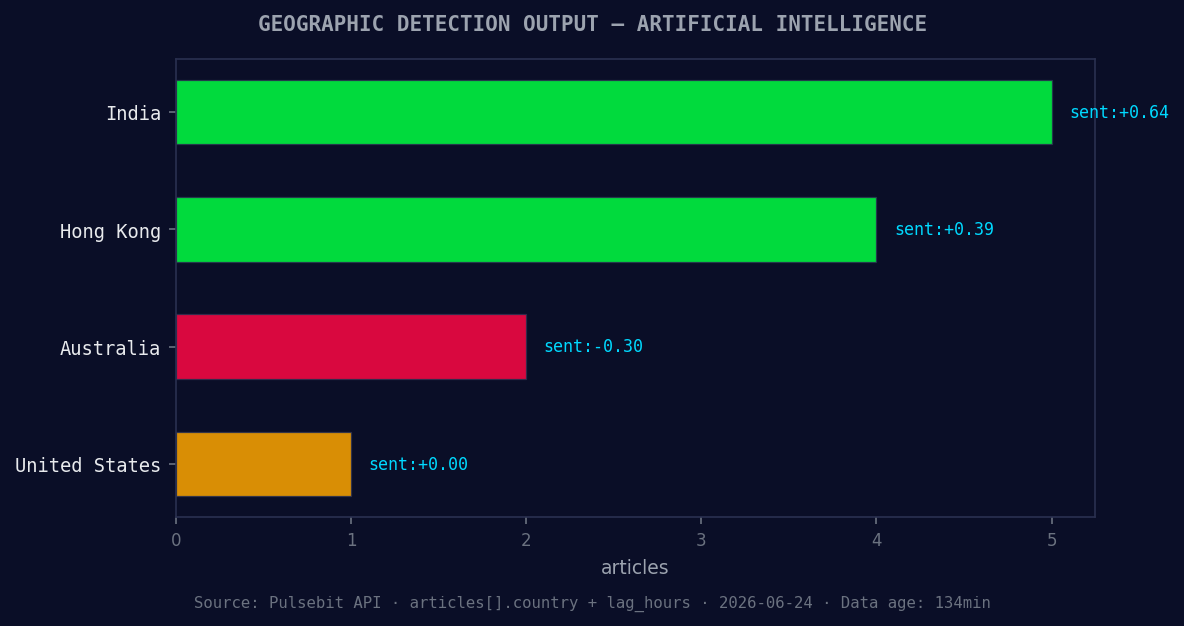
*Geographic detection output for artificial intelligence. India leads with 5 articles and sentiment +0.64. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
Now that we have the sentiment data filtered for English, we need to assess how the narrative is framed around this momentum spike. We can pass the cluster story back through our sentiment endpoint:
# Step 2: Meta-sentiment moment
meta_sentiment_url = "https://api.pulsebit.lojenterprise.com/sentiment"
cluster_reason = "Clustered by shared themes: how, jobs, india, research, robot:."
meta_params = {
"topic": "AI Firms and Manhattan Office Space",
"input": cluster_reason
}
meta_response = requests.post(meta_sentiment_url, json=meta_params)
meta_data = meta_response.json()
print(meta_data)
By running these two pieces of code, we can not only extract the sentiment data but also analyze how the narrative is evolving in real-time.
Now that we’ve caught this anomaly, what can we build with this pattern? Here are three specific ideas:
Geo-Filtered Sentiment Tracker: Create a real-time dashboard that monitors sentiment around "artificial intelligence" specifically for English-speaking regions. Set a threshold for momentum spikes above -1.0 to trigger alerts.
Meta-Sentiment Analysis Tool: Build a tool that continuously sends the clustered narrative back through the sentiment endpoint every hour. This helps gauge how the framing of topics like "AI Firms" is shifting and whether it's moving toward a more positive or negative tone.
Comparative Analysis Endpoint: Develop an endpoint that compares emerging themes in AI against mainstream topics like "how" and "jobs". Use the sentiment scores to create a visual representation of how these narratives diverge over time.
We can easily get started with all of this by visiting our documentation at pulsebit.lojenterprise.com/docs. With a few copy-paste operations, you can run this code in under 10 minutes and start capturing those critical sentiment shifts before they become trends.

Top comments (0)