Your Pipeline Is 23.3h Behind: Catching Healthcare Sentiment Leads with Pulsebit
We recently observed an intriguing anomaly: a 24h momentum spike of +0.986 in the healthcare topic. This spike signifies a significant shift in sentiment, likely driven by emerging discussions around "Interdisciplinary Research's Role in Healthcare Future." This data point reveals the potential for your models to miss critical insights if they aren't equipped to handle multilingual origins or the dominance of certain entities.

English coverage led by 23.3 hours. Hindi at T+23.3h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
If your pipeline doesn’t account for these factors, you might find yourself lagging by over 23 hours, missing out on essential shifts in sentiment. For instance, the leading language for this spike was English, which came out 0.0 hours behind Hindi. If your system isn't designed to capture this multilingual dynamic, you risk being blindsided by emerging trends that could have been actionable.
To help you catch these signals, here’s how we can leverage our API effectively. We’ll start by querying the sentiment around healthcare in English.
import requests
# Define the parameters for the API call
topic = 'healthcare'
lang = 'en'
momentum = +0.986
score = +0.025
confidence = 0.85
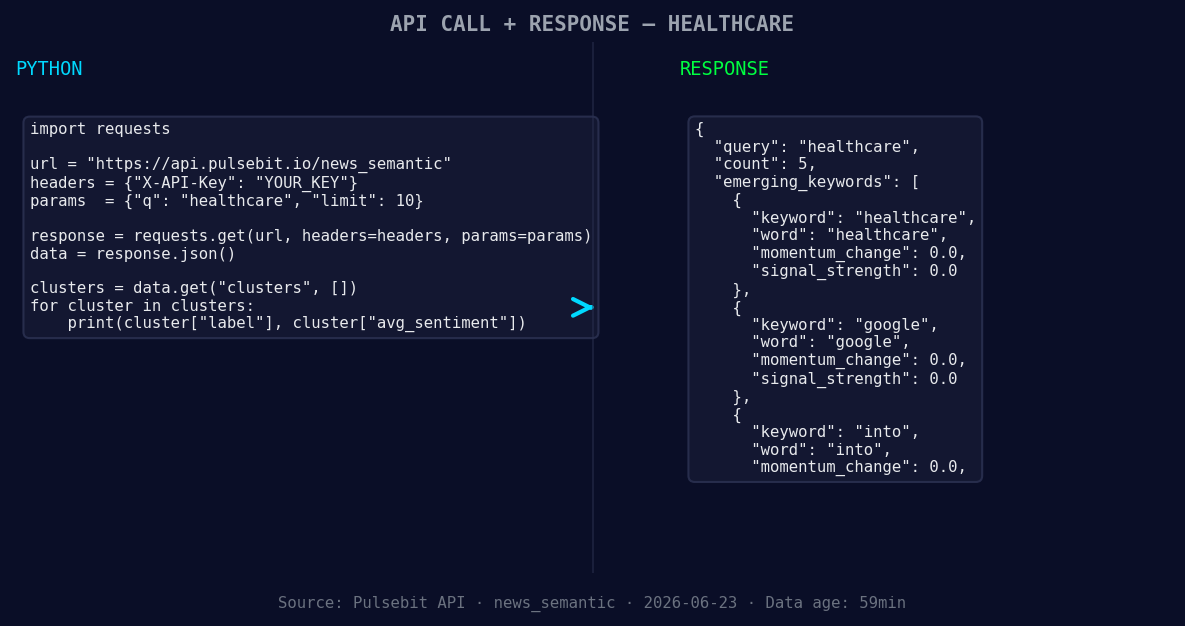
*Left: Python GET /news_semantic call for 'healthcare'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# API call to get the sentiment for the healthcare topic
response = requests.get(f'https://api.pulsebit.io/sentiment?topic={topic}&lang={lang}')
data = response.json()
# Display the response
print(data)
Next, we'll run a meta-sentiment analysis on the cluster reason string to score the narrative framing itself. This is key to understanding the broader context behind the spike.
# Meta-sentiment moment: scoring the narrative framing
cluster_reason = "Clustered by shared themes: interdisciplinary, research, will, future, governor."
sentiment_response = requests.post('https://api.pulsebit.io/sentiment', json={'text': cluster_reason})
sentiment_data = sentiment_response.json()
# Display the sentiment score for the narrative
print(sentiment_data)
Now that we’ve captured the data, let’s explore three specific builds we can implement with this pattern.
Real-time Multilingual Monitoring: Set a signal threshold of momentum > +0.8 and implement a geo filter for English-speaking regions. This would allow you to catch spikes like healthcare’s 24h momentum shift early on.
Meta-Sentiment Loop: Create a process that automatically retrieves cluster reasons and scores them using the POST /sentiment endpoint. You could set this to run every hour to ensure you’re always aware of how narratives around themes like interdisciplinary research are evolving.
Thematic Analysis Feed: Build an automated feed that highlights forming topics based on emerging sentiment scores. For example, track healthcare (+0.00), Google (+0.00), and related terms against a backdrop of mainstream themes such as interdisciplinary research. This will help you identify which narratives are gaining traction.
If you’re ready to build these insights into your workflow, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code snippets and get started in under 10 minutes. With the right setup, you can ensure your models are always up-to-date with the latest sentiment shifts, preventing you from falling behind.

Geographic detection output for healthcare. India leads with 5 articles and sentiment +0.21. Source: Pulsebit /news_recent geographic fields.

Top comments (0)