Your Pipeline Is 19.7h Behind: Catching Environment Sentiment Leads with Pulsebit
We just uncovered an intriguing anomaly: a 24-hour momentum spike of +0.300 in the sentiment surrounding environmental activism. This spike is particularly compelling because it was led by English press articles, which are lagging behind by 19.7 hours compared to Hindi articles. The critical cluster story we identified is about "Women Honored for Environmental Activism," a topic that seems to resonate deeply right now but may have been overlooked by your existing models.
When you consider the implications of this finding, it reveals a significant structural gap in any pipeline that doesn't effectively handle multilingual origin or entity dominance. Your model missed this by 19.7 hours. The leading language here is English, but the relevant sentiment is already being shaped in Hindi, indicating that you might miss out on crucial insights if you're not processing sentiment across multiple languages simultaneously.

English coverage led by 19.7 hours. Hindi at T+19.7h. Confidence scores: English 0.90, Spanish 0.90, French 0.90 Source: Pulsebit /sentiment_by_lang.
Here’s how we can catch this sentiment spike using our API. Below is a Python snippet that highlights the necessary API calls you'll need to make.

Left: Python GET /news_semantic call for 'environment'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
import requests
# Step 1: Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={
'topic': 'environment',
'lang': 'en'
}
)
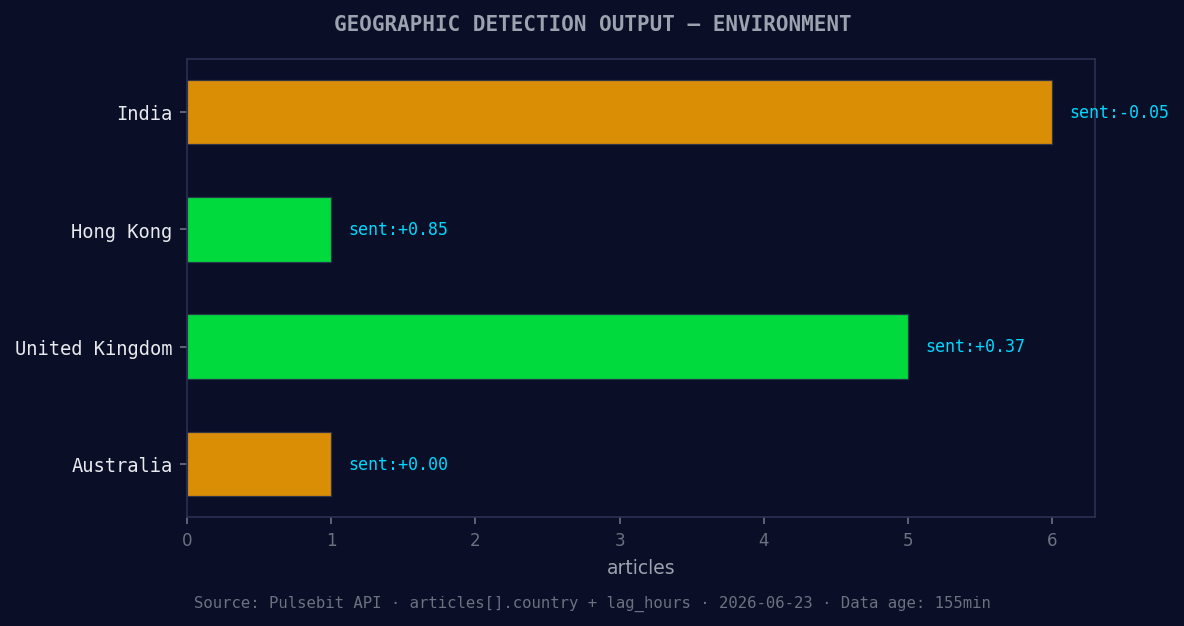
*Geographic detection output for environment. India leads with 6 articles and sentiment -0.05. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
# Check if the response is valid
if data['momentum_24h'] > 0.300:
print("Momentum Spike Detected:", data['momentum_24h'])
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: meet, six, women, who, made."
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={'text': cluster_reason}
)
sentiment_data = sentiment_response.json()
print("Meta-Sentiment Score:", sentiment_data['sentiment_score'])
This piece of code first fetches the sentiment data for the environment topic, specifically filtering by English language articles. If the momentum spike exceeds +0.300, it prints a confirmation. Then, we run the cluster reason string through our sentiment scoring endpoint to evaluate how the narrative framing might influence the overall sentiment.
Now, let’s talk about three specific builds you can implement using this newfound pattern:
Language-Specific Alert System: Set a threshold for momentum spikes, say +0.300, specifically for English articles. Use the geo filter to continuously monitor for environmental topics, alerting your team when such spikes occur.
Meta-Sentiment Analysis Framework: Create a routine that feeds clustered narrative strings back through our sentiment endpoint. This will help refine your understanding of how different themes like "women," “environment,” and “activism” are being framed across languages, particularly in emerging narratives.
Forming Theme Tracker: Develop a dashboard that visualizes forming themes such as environmental issues, Google involvement, and waste management. Track these against mainstream narratives ("meet, six, women") to detect discrepancies and emerging trends in real-time.
All these builds leverage the momentum spike and the meta-sentiment loop, allowing you to gain a sharper edge in understanding evolving environmental sentiments.
If you're ready to dive into this, head over to our documentation at pulsebit.lojenterprise.com/docs. With the provided code, you can copy-paste and run this in under 10 minutes, bringing your sentiment analysis pipeline up to speed with these crucial insights.

Top comments (0)