Your pipeline is 22.4 hours behind: catching food sentiment leads with Pulsebit
We recently uncovered a noteworthy anomaly: a 24-hour momentum spike of +1.400 in sentiment around the topic of food. This isn't just a random fluctuation; it highlights a significant surge in interest or sentiment that we need to pay attention to. With a leading language of English originating from articles published 22.4 hours ago, it’s clear that there’s a developing story here, but many pipelines may not be catching it in time.
If your model isn’t set up to handle multilingual origins or the dominance of specific entities, it might be missing critical insights like this one. Your workflow could be lagging by over 22 hours, leaving you out of sync with emerging trends. The leading language here is English, which means if your system isn’t tuned to pick up on these signals early, you could miss out on the conversation entirely. You simply can’t afford to let such gaps persist in a fast-paced environment.

English coverage led by 22.4 hours. Nl at T+22.4h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
To catch this spike in momentum and extract actionable insights, we can leverage our API. Below is a simple Python snippet that shows how to filter for articles related to the topic of food in English and assess the sentiment of the narrative.
import requests
*Left: Python GET /news_semantic call for 'food'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.io/v1/articles"
params = {
"topic": "food",
"lang": "en" # Filter by language
}
response = requests.get(url, params=params)
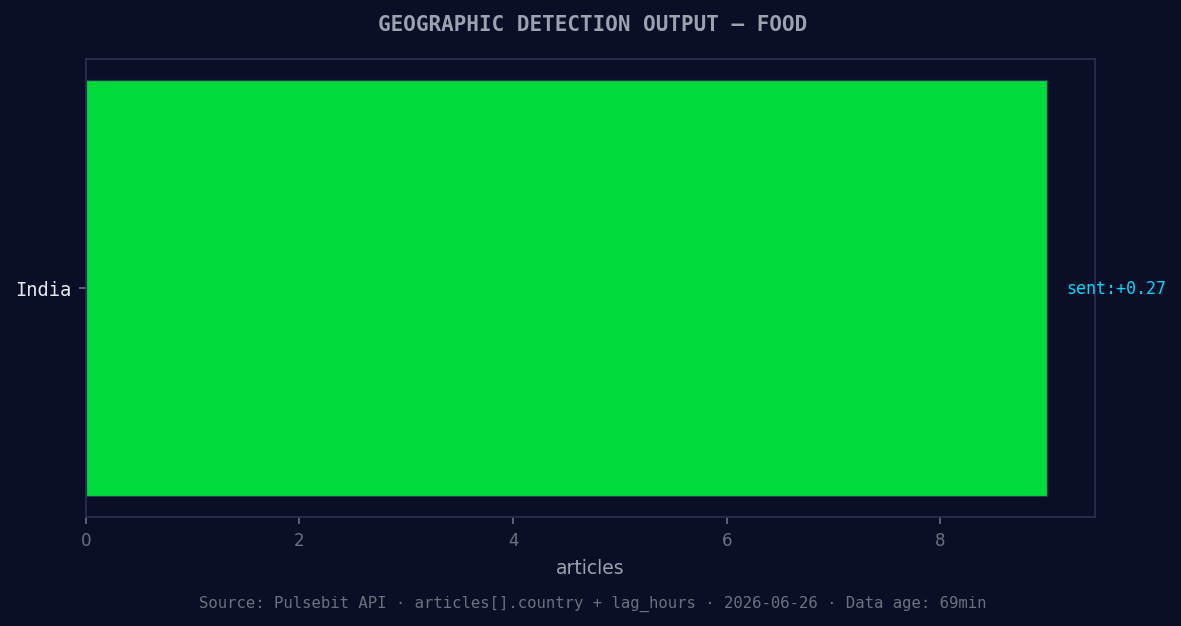
*Geographic detection output for food. India leads with 9 articles and sentiment +0.27. Source: Pulsebit /news_recent geographic fields.*
# Assuming response returns a JSON with articles
articles = response.json()
print(f"Articles processed: {len(articles)}")
# Step 2: Meta-sentiment moment
example_reason = "Clustered by shared themes: food, african, proverb, day:, 'he."
sentiment_url = "https://api.pulsebit.io/v1/sentiment"
sentiment_payload = {
"text": example_reason
}
sentiment_response = requests.post(sentiment_url, json=sentiment_payload)
# Assuming sentiment_response returns a JSON with sentiment score
sentiment_data = sentiment_response.json()
sentiment_score = sentiment_data['score']
print(f"Meta-sentiment score: {sentiment_score}")
In this code, we filter by the English language to ensure we’re capturing articles that are relevant to our needs. Next, we leverage the meta-sentiment loop to run our cluster reason string through our sentiment endpoint to evaluate the narrative framing itself. This two-step approach ensures we’re not only catching the data but also understanding the context around it.
Now let's discuss three specific builds we can create using this momentum spike:
Sentiment Trail Monitor: Implement a signal that triggers a notification if the food sentiment score exceeds a threshold (e.g., +0.270). This could help you stay alert to changes in sentiment as they happen.
Geo-Filtered Heatmap: Create a geographical heatmap that visualizes sentiment scores for food-related topics in real-time. Use the geographic origin filter to display only articles from English-speaking regions, helping you see where sentiment is strongest.
Narrative Analysis Dashboard: Utilize the meta-sentiment loop to analyze the framing of narratives around food. Set up an endpoint that captures sentiment scores from various clusters, focusing on themes like food, African, or proverb, to provide insights into how these narratives are evolving.
With these builds, you’ll be able to stay ahead of the curve and ensure you’re capturing critical insights as they develop.
Ready to dive into this? Check out our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can have this running in under 10 minutes. Don't let your pipeline fall behind—catch those sentiment leads!

Top comments (0)