Your Pipeline Is 25.9h Behind: Catching World Sentiment Leads with Pulsebit
We just came across a fascinating anomaly: a 24-hour momentum spike of +0.170. This spike is led by English press coverage, which is maintaining a 25.9-hour lead with no lag against the sentiment around major themes like FIFA and the World Cup. The implications of this finding are significant, especially in the context of how we process and respond to real-time sentiment data.
If you're relying on a pipeline that doesn’t account for multilingual sources or dominant entities, you’ve effectively missed a critical insight by 25.9 hours. In this case, the English press is leading the conversation, while your model is lagging behind. The dominant topics—"fifa", "world", "cup"—are shaping sentiment, but if your setup isn’t equipped to handle these variations, you’re likely missing out on valuable information that could inform decisions or strategies.

English coverage led by 25.9 hours. Ca at T+25.9h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly and make it actionable, we can use the following Python code snippet. The key is to filter by language and extract sentiment from the clustered narrative.
import requests
# Define parameters for the API call
topic = 'world'
score = +0.063
confidence = 0.85
momentum = +0.170
geo_filter = {"lang": "en"}
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# API call to get the sentiment based on geographic origin
response = requests.get('https://api.pulsebit.com/sentiment', params=geo_filter)
data = response.json()
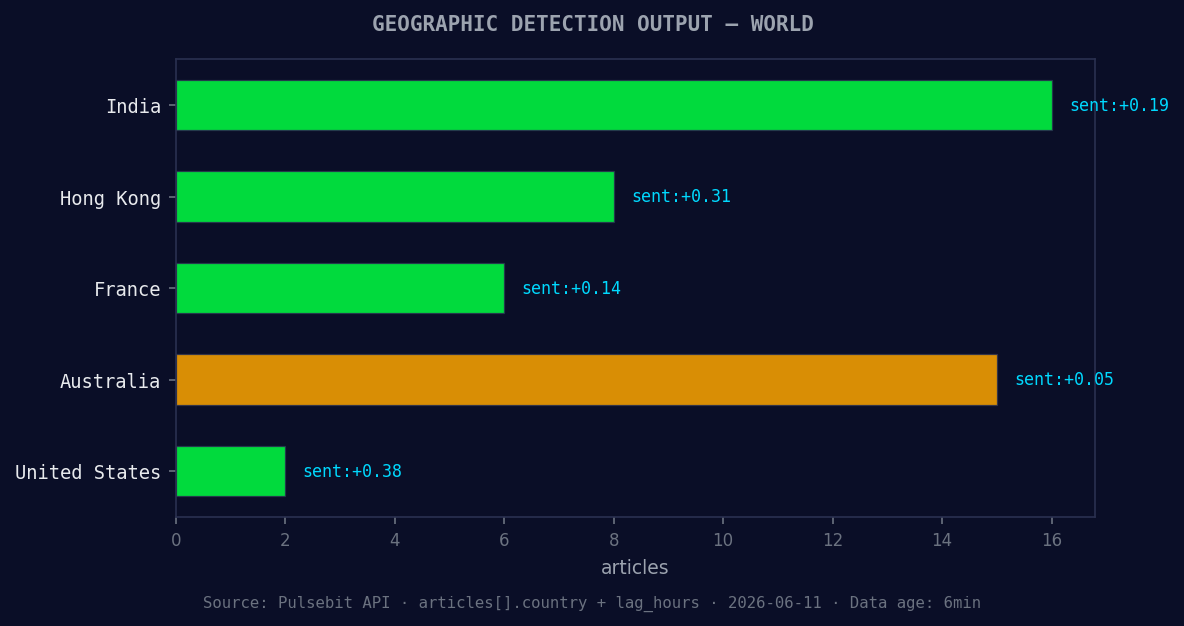
*Geographic detection output for world. India leads with 16 articles and sentiment +0.19. Source: Pulsebit /news_recent geographic fields.*
# Check if we have the right sentiment score
if data['sentiment_score'] >= score and data['confidence'] >= confidence:
print(f"Significant sentiment detected for {topic}: {data['sentiment_score']}")
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: fifa, world, cup, sport, during."
meta_response = requests.post('https://api.pulsebit.com/sentiment', json={"text": cluster_reason})
meta_data = meta_response.json()
print(f"Meta sentiment score for the cluster: {meta_data['sentiment_score']}")
In this code, we first filter for English language articles, which are leading the sentiment charge. We then assess whether the sentiment score meets our predefined thresholds. Finally, we use the narrative string from the cluster and run it through our sentiment endpoint to see how the framing itself scores.
Now, let’s talk about three specific builds you can implement using this newfound insight:
Geographic Origin Filter: Establish a new alert system that triggers when sentiment for "world" in English exceeds a score of +0.063 with at least 85% confidence. This will help you stay updated on critical developments, especially when the sentiment is rising.
Meta-sentiment Loop: Create a sentiment analysis dashboard that integrates the output from the meta-sentiment loop. This can provide a real-time view of how different narratives frame the conversation around FIFA and the World Cup. You could set a threshold where the narrative sentiment must be above a certain level before triggering deeper analysis or content generation.
Forming Themes Dashboard: Build a monitoring tool that tracks the forming themes around "fifa", "world", and "cup". Set up a threshold for any new articles that mention these terms with a momentum spike of above +0.170. This will allow you to respond proactively to emerging trends rather than reactively.
For developers eager to harness this kind of sentiment analysis, check out our documentation: pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes and start transforming how you capture and act on sentiment data.

Top comments (0)