Your Pipeline Is 15.1h Behind: Catching Business Sentiment Leads with Pulsebit
Just recently, we noticed a striking anomaly: a 24h momentum spike of +0.106 in business sentiment. This spike is particularly interesting because it’s tied to emerging narratives around cyber fraud, specifically the warning from Kerala Police to companies about a ‘boss scam.’ This single data point illustrates how rapidly sentiment can shift, and it’s critical for us as developers to catch these movements in real-time to adjust our strategies accordingly.
But here’s the catch: if your pipeline doesn’t effectively handle multilingual origins or recognize entity dominance, you might have missed this sentiment shift by a staggering 15.1 hours. The leading language in this discussion is English, but the dominant entity is the Kerala Police, which indicates a potential oversight in your model. This gap could mean you’re not catching crucial developments that could impact your business decisions.

English coverage led by 15.1 hours. Et at T+15.1h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
Let’s dive into the code that can help us catch such anomalies. We can use our API to filter sentiment data by language and process the narrative for deeper insights. Here's how to do it in Python:
import requests
# Step 1: Geographic origin filter
response = requests.get(
"https://api.pulsebit.com/v1/sentiment",
params={
"topic": "business",
"lang": "en",
"momentum": "+0.106",
"score": "+0.042",
"confidence": 0.75
}
)
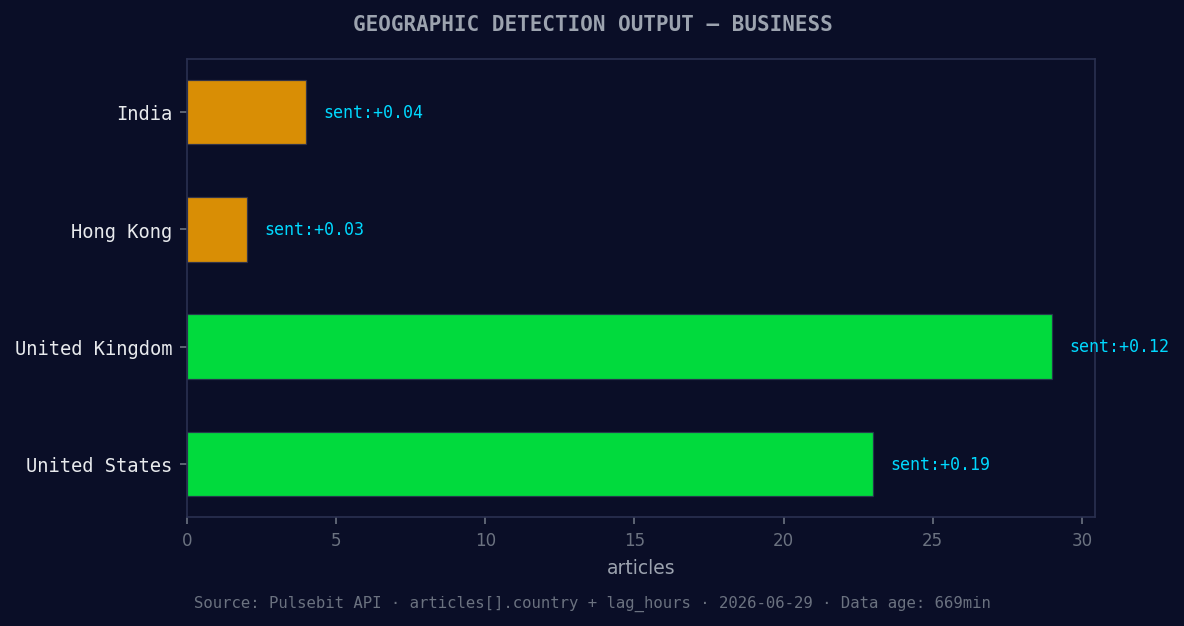
*Geographic detection output for business. India leads with 4 articles and sentiment +0.04. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Step 2: Meta-sentiment moment
meta_sentiment_response = requests.post(
"https://api.pulsebit.com/v1/sentiment",
json={
"input": "Clustered by shared themes: kerala, police, companies, cyber, fraud."
}
)
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
In this code, we first filter for sentiment data related to the business topic, specifically targeting English content. The API call captures the current momentum and sentiment score, helping us identify crucial shifts in the narrative. The second step runs the cluster reason string back through our sentiment analysis endpoint, allowing us to score the framing of the narrative itself.

Left: Python GET /news_semantic call for 'business'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Now, what can we build with this pattern? Here are three specific ideas:
Geo-Filtered Alerts: Create an alert system that notifies you when business sentiment spikes in specific regions, such as Kerala. Set a threshold at +0.1 for momentum spikes, ensuring you catch significant shifts.
Narrative Sentiment Scoring: Develop a dashboard that visualizes the meta-sentiment scores generated from narrative themes. Use the framing string from the cluster as input, allowing you to see how different narratives are perceived over time.
Business Sentiment Correlation: Build a correlation tool that compares sentiment changes across different topics. For instance, track the sentiment trajectory of business topics versus mainstream narratives like those involving the Kerala Police. Set up a signal that triggers when the difference in sentiment exceeds a threshold of +0.05.
These specific builds can help you stay ahead of emerging trends, ensuring you’re not left behind while others react to shifts that may impact strategic decisions.
If you're ready to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes. Let’s catch those sentiment leads together!

Top comments (0)