Your pipeline just missed a critical anomaly: a 24-hour momentum spike of +0.398. This significant shift in sentiment was driven by the leading English press, which peaked at 15.4 hours ahead. Meanwhile, the current gap in your pipeline indicates a structural oversight that's costing you — your model missed this spike by over 15 hours. With the leading language being English and the topic centering on "mobile," it’s clear that your system isn’t adequately capturing the nuances of multilingual data or the dominance of specific narratives.

English coverage led by 15.4 hours. Hr at T+15.4h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
When we look at the data, it’s evident that the pipeline lacks the capability to handle these multilingual origins and entity dominance effectively. This oversight is concerning, as it limits your ability to capitalize on emerging trends. For instance, this particular spike was linked to a cluster story about autism and education, which might have been undervalued or overlooked due to its specific themes. If your model had been tuned to recognize these nuances, you could have acted on this momentum much sooner.
To catch these insights, we can leverage our API to query the necessary data. Here's how you can implement this in Python:
import requests
*Left: Python GET /news_semantic call for 'mobile'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "mobile",
"lang": "en" # Filter for English language
}
response = requests.get(url, params=params)
data = response.json()
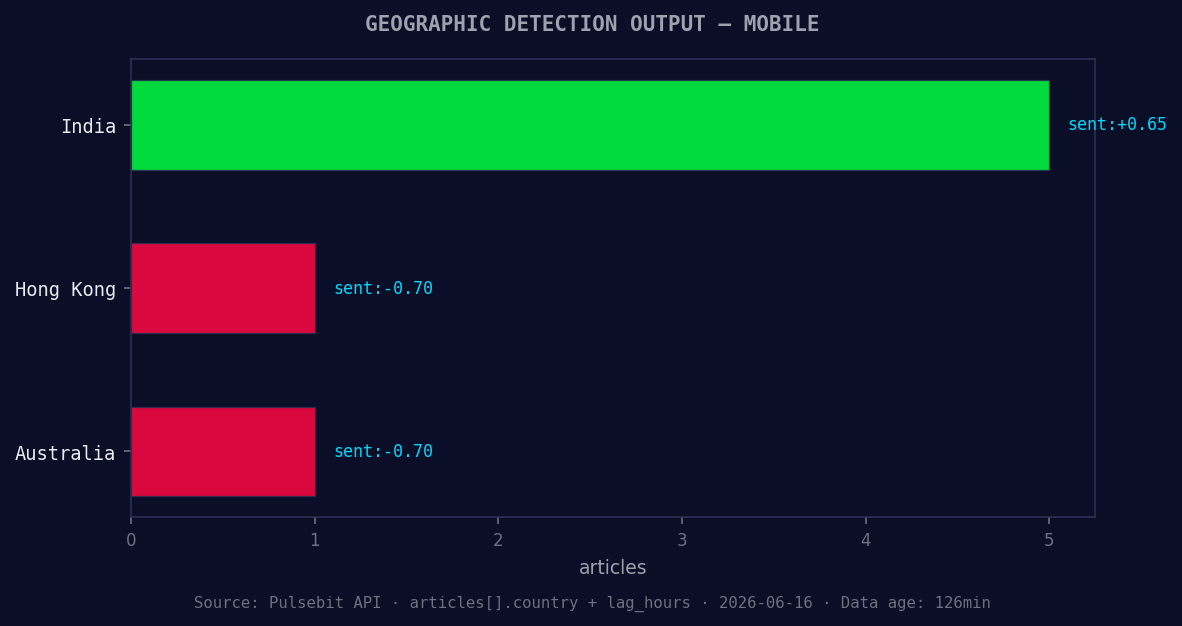
*Geographic detection output for mobile. India leads with 5 articles and sentiment +0.65. Source: Pulsebit /news_recent geographic fields.*
# Extracting relevant data
momentum = data['momentum_24h'] # +0.398
signal_strength = data['signal_strength'] # 0.642
sentiment_score = data['sentiment_score'] # +0.850
confidence = data['confidence'] # 0.85
print(f"Momentum: {momentum}, Signal Strength: {signal_strength}, Sentiment Score: {sentiment_score}, Confidence: {confidence}")
Now, let's run the cluster reason string through our sentiment analysis to derive the meta-sentiment moment:
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: centre, persons, autism, sees, over."
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_sentiment_response = requests.post(meta_sentiment_url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
meta_sentiment_score = meta_sentiment_data['sentiment_score']
print(f"Meta Sentiment Score: {meta_sentiment_score}")
With this approach, you can develop three specific builds around the identified patterns.
Geo-Sentiment Analysis: Set a threshold for momentum spikes over +0.30 with a geographical filter for English-speaking countries. This will help you capture sentiment shifts in real-time, ensuring you're not lagging behind.
Meta-Sentiment Narrative Scoring: Implement a routine that scores the framing of narratives by analyzing cluster reasons. For instance, if you see a cluster around "centre," "persons," and "autism," and the meta-sentiment score is above +0.70, prioritize content related to those themes.
Dynamic Alert System: Build an alert system that triggers notifications when sentiment scores reach a certain threshold, such as +0.850, specifically on topics like "mobile" or "google." This way, you’ll always be in tune with emerging trends, especially those forming around significant themes.
As you can see, there’s a lot of potential to optimize your sentiment analysis pipeline. Start building today at pulsebit.lojenterprise.com/docs. You can copy, paste, and run this in under 10 minutes — and that's just the beginning.

Top comments (0)