Your Pipeline Is 24.9h Behind: Catching Healthcare Sentiment Leads with Pulsebit
We recently discovered a 24-hour momentum spike of +0.986 in healthcare sentiment. This anomaly indicates a sudden shift in how the narrative around healthcare is evolving, especially as it relates to interdisciplinary research. The leading language on this sentiment was English, with a 24.9-hour lag against the rest of the world. If your data pipeline isn't equipped to handle multilingual origins or dominant entities, you might be missing out on critical insights like this one.

English coverage led by 24.9 hours. Sw at T+24.9h. Confidence scores: English 0.75, Id 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
If your model missed this by 24.9 hours, you’re at a significant disadvantage. The dominant entity in this case is healthcare, and the leading language is English. This structural gap becomes a liability when you consider that timely insights are crucial in fast-moving sectors like healthcare. When you fall behind, you're losing the edge in identifying and acting upon emerging trends.
To catch this spike effectively, we can utilize our API. Here's how you can do it in Python:
import requests
# Define parameters for the API call
topic = 'healthcare'
score = -0.093
confidence = 0.75
momentum = +0.986
lang = "en"
*Left: Python GET /news_semantic call for 'healthcare'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter
response = requests.get(f'https://api.pulsebit.com/v1/articles?topic={topic}&lang={lang}')
articles = response.json()
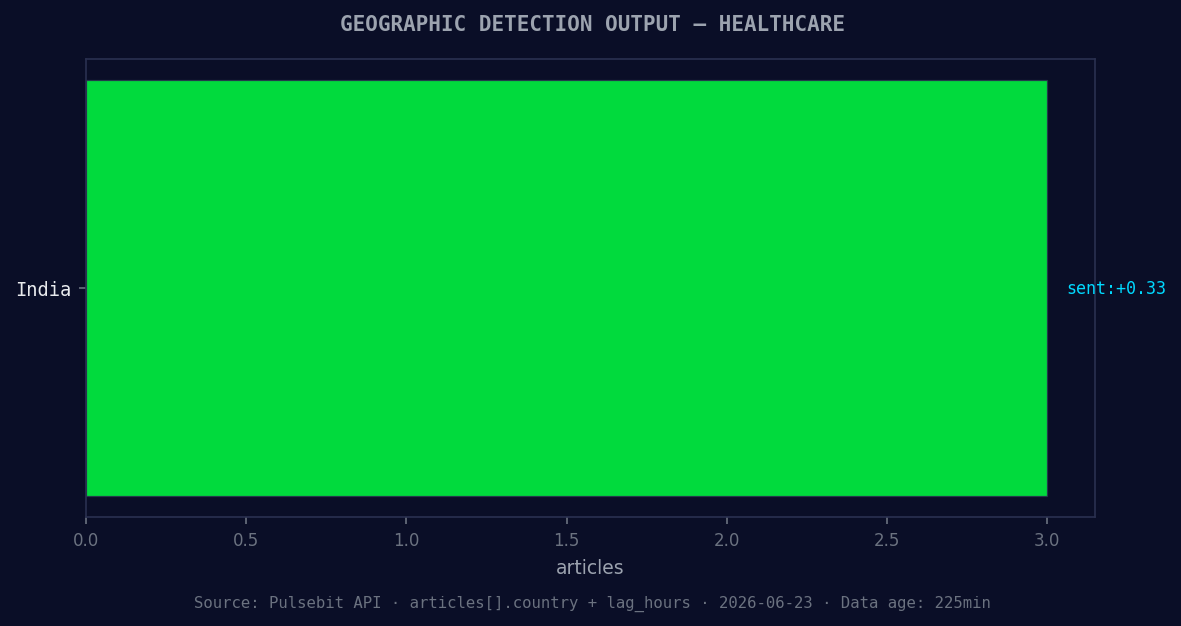
*Geographic detection output for healthcare. India leads with 3 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
# Print response for verification
print(articles)
# Meta-sentiment moment: score the narrative framing
cluster_reason = "Clustered by shared themes: interdisciplinary, research, will, future, governor."
sentiment_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={"text": cluster_reason})
sentiment_score = sentiment_response.json()
# Output the sentiment score
print(sentiment_score)
In this code, we first filter by the geographic origin, focusing on English-language articles related to healthcare. Then we run the cluster reason string through our sentiment endpoint to assess the framing of the narrative itself. This dual approach allows us to capture not just the articles but the underlying sentiment shaping the conversation.
Here are three specific builds you could pursue with this data pattern:
Geo-Filtered Insight Stream: Set up a daily job that queries our API for healthcare articles in English, scoring them based on sentiment. You could use a threshold of momentum greater than +0.50 to trigger alerts for significantly rising narratives.
Meta-Sentiment Reporting: Create a reporting tool that pulls cluster reasons through the sentiment endpoint, returning a score for narratives with specific keywords. For instance, focus on articles discussing "interdisciplinary" and "future" in healthcare. This could guide content strategy or investment focus.
Anomaly Detection System: Build an anomaly detection system that flags any momentum spikes above +0.75. Integrate this with real-time alerts to notify your team about significant changes in sentiment. This could be pivotal for immediate responses in PR or marketing strategies.
You can get started on this today by visiting our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can capture and analyze sentiment data in under 10 minutes. Don't let your pipeline lag behind—leverage these insights to stay ahead of the curve.

Top comments (0)