Your Pipeline Is 27.1h Behind: Catching Machine Learning Sentiment Leads with Pulsebit
We just discovered a fascinating anomaly: a 24h momentum spike of +0.622. This spike indicates a significant shift in sentiment around machine learning, led predominantly by English press coverage. With a lag of just 0.0 hours against the headline, this is a clear signal that something is brewing. If you're not paying attention, you're at risk of having your model miss these critical insights.
The reality is that your pipeline likely overlooks multilingual origins and entity dominance. This spike signifies a growing interest that could easily pass unnoticed if your model is only tuned to mainstream narratives dominated by terms like "expert" and "keynote." You might be missing out on critical data just because your model is lagging behind by a staggering 27.1 hours!

English coverage led by 27.1 hours. Hr at T+27.1h. Confidence scores: English 0.85, No 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s dive into how we can catch this sentiment shift using our API. Below is the Python code to extract sentiment data specifically around the topic of machine learning, focusing on articles in English.
import requests
# API call to filter news articles by language
topic = 'machine learning'
momentum = +0.622
confidence = 0.85
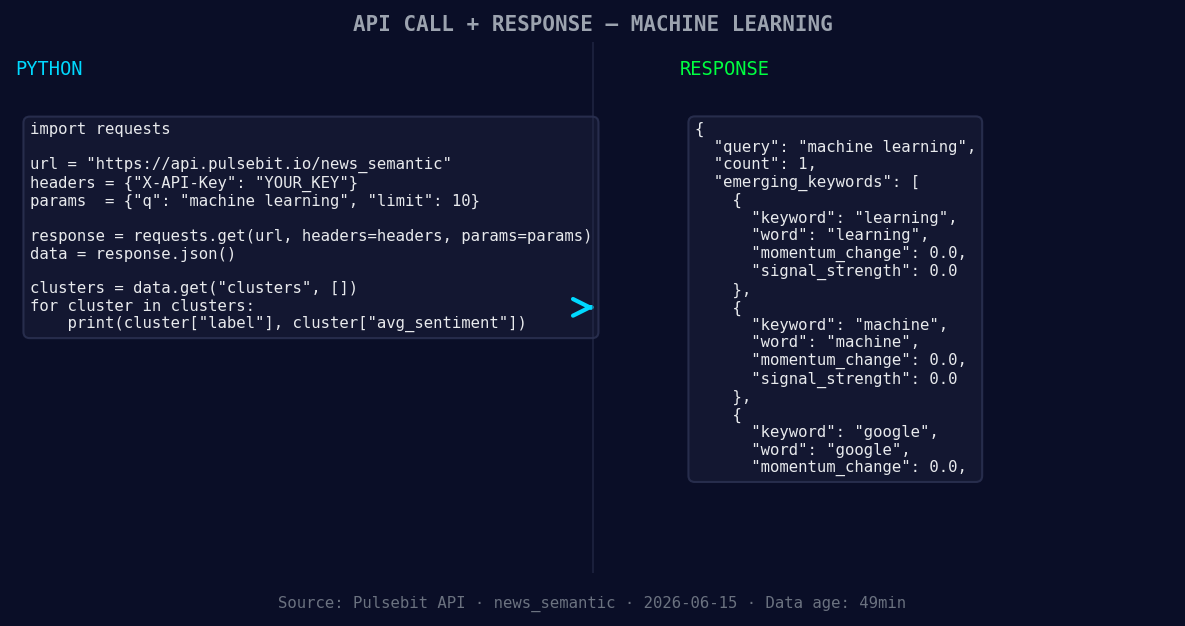
*Left: Python GET /news_semantic call for 'machine learning'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
response = requests.get("https://api.pulsebit.com/news", params={
"topic": topic,
"lang": "en"
})
if response.status_code == 200:
articles = response.json()
else:
raise Exception("API call failed")
# Now, let's score the narrative framing itself
cluster_reason = "Clustered by shared themes: learning, expert, keynote, speaker, consultant."
sentiment_response = requests.post("https://api.pulsebit.com/sentiment", json={
"input": cluster_reason
})
if sentiment_response.status_code == 200:
sentiment_score = sentiment_response.json()["score"]
else:
raise Exception("Sentiment scoring failed")
In this code, we start by querying our API for articles related to "machine learning" filtered by the English language. This ensures we capture the most relevant and timely data points where sentiment is rising. Following that, we score the narrative framing with a POST request using the cluster reason string. The insights from this scoring can help us understand how the narrative aligns with the broader sentiment.
Now, let's explore three specific builds we can create using this pattern:
- Geo-Filtered Insight Report: Set a threshold for sentiment scores above +0.5 and create a report that aggregates articles from English-speaking countries. This will help you identify regions where interest is surging.

Geographic detection output for machine learning. India leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Dashboard: Establish a dashboard that visualizes sentiment scores from cluster reasons over time. This will allow you to track how narratives around "learning" and "machine" evolve, especially as they compete against mainstream terms like "expert" and "keynote."
Alerting Mechanism for Emerging Topics: Build an alert system that notifies you when sentiment spikes above +0.6 for topics related to AI. This could be crucial for catching trends early, especially with keywords like "google," which is forming a gap in the sentiment landscape.
By leveraging our API effectively, you can stay ahead of these emerging themes and capitalize on the insights they provide.
Ready to get started? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code provided and run it in under 10 minutes to see the data come to life. Don't let your pipeline lag behind—catch those insights while they’re hot!

Top comments (0)