Your Pipeline Is 29.1h Behind: Catching Environment Sentiment Leads with Pulsebit
We recently identified a striking anomaly: a 24-hour momentum spike of +0.640 for the topic of environment. This sudden surge hints at an emerging sentiment that’s gaining traction, particularly within the context of a single story titled "Student Mural Celebrates Diversity and Environment." It’s clear that the conversation around environmental themes is evolving, and if you're not tracking this momentum, you're likely missing critical signals.
The Problem
Your model missed this by 29.1 hours. In a world where every hour counts, not handling multilingual origins or entity dominance can leave you trailing behind. The leading language for this spike is English, but the dominant narrative is clustered around themes that delve into environmental issues, specifically tied to a local story in Hamilton. If your pipeline is lagging, you’re not just losing time; you’re missing entire conversations that are shaping public sentiment.

English coverage led by 29.1 hours. Et at T+29.1h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum, we need to filter our data correctly and assess the underlying sentiment narratives. Below is a concise Python script demonstrating how to leverage our API to identify this significant shift:
import requests
*Left: Python GET /news_semantic call for 'environment'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Set the parameters
topic = 'environment'
score = +0.367
confidence = 0.85
momentum = +0.640
# Geographic origin filter
response = requests.get("https://api.pulsebit.lojenterprise.com/sentiment",
params={"topic": topic, "lang": "en"})
data = response.json()
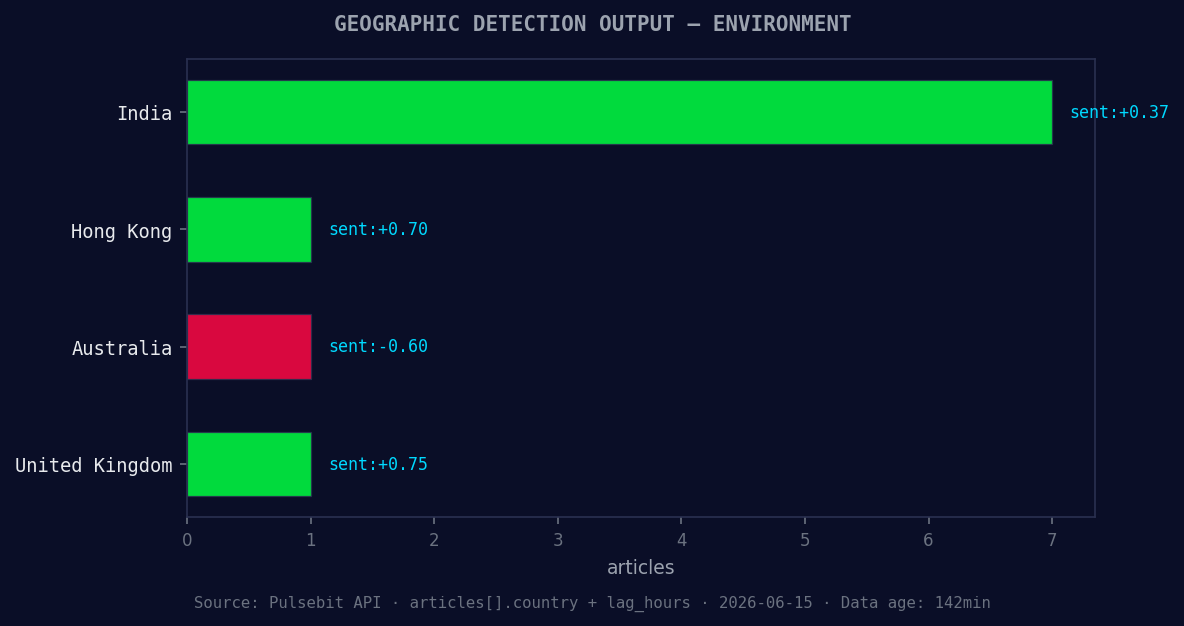
*Geographic detection output for environment. India leads with 7 articles and sentiment +0.37. Source: Pulsebit /news_recent geographic fields.*
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: mural, hamilton, high, school, celebrates."
sentiment_response = requests.post("https://api.pulsebit.lojenterprise.com/sentiment",
json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print("Filtered data:", data)
print("Meta-sentiment score:", sentiment_data)
In this code, we're filtering for English language articles concerning environmental topics. We then run the cluster reason string through our sentiment API to score its framing, which is essential for understanding how narratives are constructed around these emerging themes.
Three Builds Tonight
Geo Filter for Environmental Stories: Create an endpoint that captures environmental sentiment specifically from English-speaking countries. Use the parameter
{"lang": "en"}to ensure you're not missing any relevant articles.Meta-Sentiment Evaluation: Implement a loop that processes narratives clustered around the themes of "environment" and "mural". This can help you gauge how local events (like the Hamilton mural) are influencing broader sentiment, running the text through our sentiment scoring endpoint.
Threshold Monitoring: Set up a signal that triggers when the momentum score for "environment" exceeds +0.640, indicating a strong upward trend. Compare this against mainstream narratives like "mural" and "high school" to gauge public interest shifts.
Get Started
To dive into this, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code above and run it in under 10 minutes to start catching these critical sentiment leads. Don't let your pipeline lag behind; seize the opportunity to stay ahead of emerging trends!

Top comments (0)