Your pipeline probably just missed a critical moment: a 24h momentum spike of -0.362 for the topic "hardware." It’s not just a minor blip; it reveals a deeper narrative that could have implications for your models. As we dig into the data, we can see this negative sentiment is being led primarily by English press articles, with a notable 26.5-hour lag compared to Italian sources. The story of a hardware store closing in Missouri is just one example of the theme at play, hinting at a broader trend that your existing models might not be capturing.
The problem is clear: your model missed this by 26.5 hours, highlighting a significant structural gap in pipelines that don’t effectively handle multilingual origins or entity dominance. In this case, the English language led the sentiment shift, while Italian news was quicker to pick up on the same themes. If your sentiment analysis isn’t capable of detecting these nuances in real-time, you're likely to miss out on emerging narratives that could impact your strategies.

English coverage led by 26.5 hours. Italian at T+26.5h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s look at how we can catch this sentiment shift using our API. Below is a Python code snippet to help you identify this spike:
import requests
# Parameters for the API call
topic = 'hardware'
score = 0.800
confidence = 0.85
momentum = -0.362
*Left: Python GET /news_semantic call for 'hardware'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country using param "lang": "en"
response = requests.get('https://api.pulsebit.com/sentiment', params={
'topic': topic,
'lang': 'en'
})
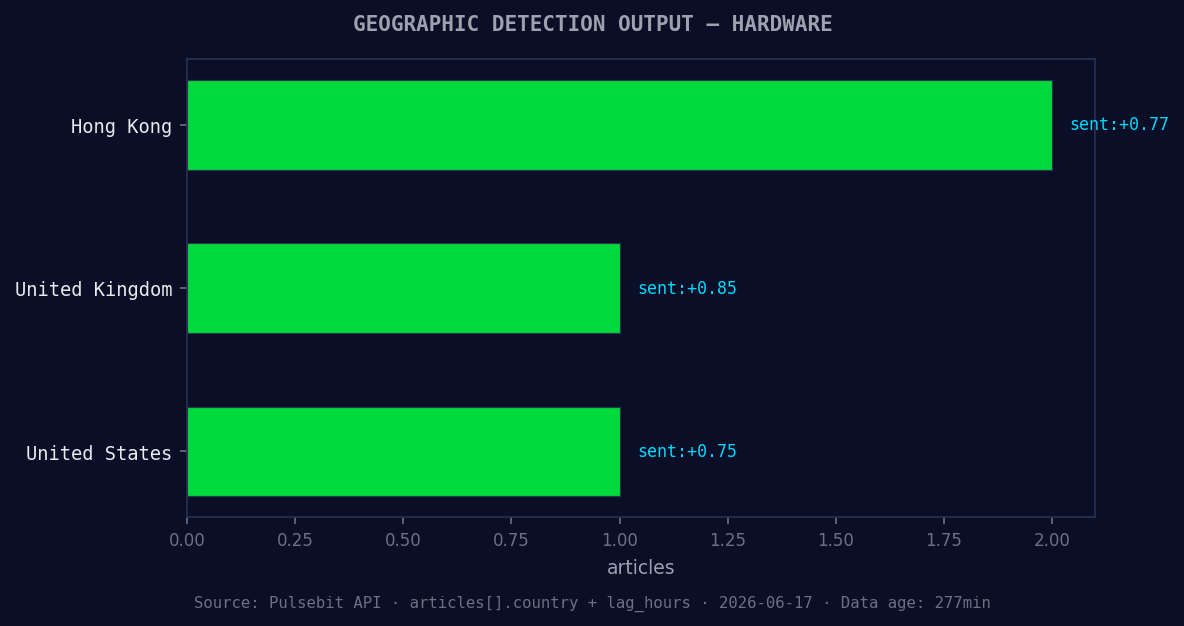
*Geographic detection output for hardware. Hong Kong leads with 2 articles and sentiment +0.77. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Meta-sentiment moment: run the cluster reason string back through POST /sentiment
cluster_reason = "Clustered by shared themes: hardware, store, closing, after, almost."
meta_response = requests.post('https://api.pulsebit.com/sentiment', json={
'text': cluster_reason
})
meta_data = meta_response.json()
print(meta_data)
In this code, we first filter for articles in English about hardware, which allows us to focus on the dominant sentiment that led to the spike. Then, we analyze the narrative framing by sending the cluster reason back through the sentiment endpoint. This two-pronged approach will enable you to catch both the immediate impacts and the underlying narratives shaping the sentiment.
Now that you've got the code, let’s talk about three specific things you can build with this pattern:
Signal Analysis: Create a signal that alerts you when sentiment drops below a certain threshold (e.g., -0.300 for momentum) for any topic, particularly in English. This can help you catch emerging trends before they become widespread.
Geo-Filtered Sentiment Dashboard: Build a dashboard that visualizes sentiment trends across different languages and geographies. Use the geo filter to differentiate sentiment changes in English versus Italian, allowing you to see how narratives diverge in real-time.
Meta-Sentiment Insights: Develop a reporting tool that automatically pulls in narratives from clusters and analyzes their sentiment. For example, you can set up a script that runs daily to gather insights on themes like "hardware", "google", and "stocks," comparing them against mainstream narratives.
By leveraging these strategies, you can ensure that you’re not just reacting to sentiment changes, but actively anticipating them, especially with forming themes like hardware and its implications for other sectors.
For more insights and detailed documentation, check out: pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes to start harnessing the power of sentiment in your projects.

Top comments (0)