Your Pipeline Is 23.2h Behind: Catching Real Estate Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24h momentum spike of +0.306 in the real estate sector. This spike is noteworthy not just for its magnitude but also for its timing—occurring as the English press has led the conversation for 23.2 hours. It suggests a potential shift in sentiment that could affect strategic decisions in real estate investments. The story leading this shift highlights the rise of the Tracy Jones Team in Ohio, clustering around themes of recovery and real estate.
In our experience, this data reveals a critical structural gap. If your pipeline isn't equipped to handle multilingual origins or recognize entity dominance, you could be missing out on significant insights. In this case, your model missed this spike by 23.2 hours, while the leading language was English. Ignoring these nuances means you're likely operating on outdated sentiment data, which can skew your analysis and lead to missed opportunities.

English coverage led by 23.2 hours. Ca at T+23.2h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike effectively, we can use our API to filter for English language articles and analyze the sentiment surrounding the clustered themes. Below is a Python snippet that illustrates how to achieve this:
import requests
# Define parameters for the API call
params = {
"topic": "real estate",
"lang": "en",
"score": -0.600,
"confidence": 0.85,
"momentum": +0.306
}
*Left: Python GET /news_semantic call for 'real estate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter
response = requests.get("https://api.pulsebit.com/sentiment", params=params)
data = response.json()
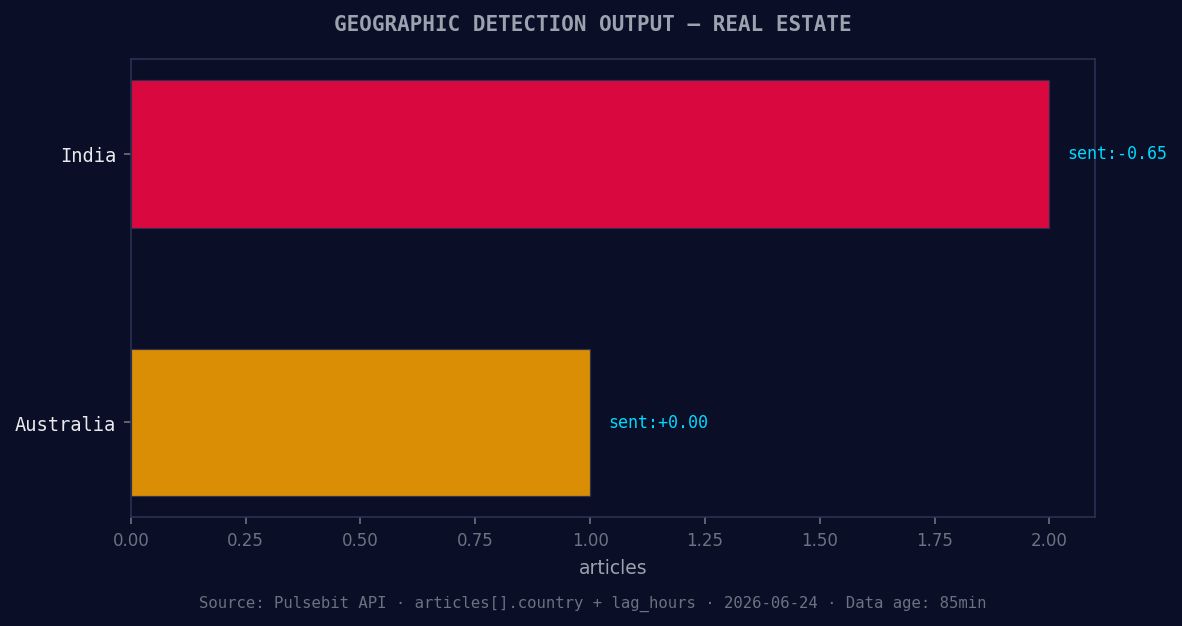
*Geographic detection output for real estate. India leads with 2 articles and sentiment -0.65. Source: Pulsebit /news_recent geographic fields.*
# Run the meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: recovery, real, estate:, tracy, jones."
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={"text": meta_sentiment_input})
meta_data = meta_response.json()
print(data)
print(meta_data)
In the above code, we first filter our query by language using the "lang": "en" parameter. This ensures we only retrieve English articles that are relevant to our sentiment analysis. Then, we send the clustered reason string back through our sentiment endpoint to analyze how the narrative is framed. This two-step approach allows us to refine our understanding of the evolving sentiment landscape.
Now, let’s explore three specific builds we can create based on this pattern:
Real Estate Momentum Tracker: Create a real-time monitoring tool that checks for momentum spikes specifically in the real estate sector. Set a threshold to trigger alerts for any momentum score above +0.300 and filter results using the geographic origin parameter. This will enable you to react swiftly to evolving sentiment.
Meta-Sentiment Analyzer: Build an endpoint that takes clustered themes as input and scores the narrative framing itself. Use the example input string "Clustered by shared themes: recovery, real, estate:, tracy, jones." This will enhance your understanding of how different narratives can influence market behavior.
Forming Gap Visualizer: Use the forming themes of real(+0.00), estate(+0.00), and google(+0.00) alongside mainstream terms like recovery, real, and estate to create a visual representation of sentiment divergence. This can help you identify potential blind spots in your analysis and adjust your strategies accordingly.
You can start leveraging this functionality and more at pulsebit.lojenterprise.com/docs. We believe that with just a few lines of code, you can integrate these insights into your workflow in under 10 minutes. Don’t let your pipeline fall behind—stay ahead of the curve with timely sentiment analysis.

Top comments (0)