Your Pipeline Is 24.0h Behind: Catching Film Sentiment Leads with Pulsebit
We recently observed a notable anomaly in our sentiment analysis: a 24h momentum spike of +0.750. This spike highlights a growing interest in film-related topics, specifically triggered by two articles discussing Kieron Moore and taboo subjects in cinema. Such a sharp rise in sentiment can be a treasure trove for developers like us, but it also exposes a critical gap in any pipeline that isn't designed to handle multilingual origins effectively.

English coverage led by 24.0 hours. Sl at T+24.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
If your model isn’t equipped to manage entity dominance and diverse linguistic inputs, you might have missed this significant shift by a full 24 hours. With English press leading the charge, this delay could mean losing out on valuable insights that could inform your content strategy or trading decisions. Ignoring these nuances can hinder your ability to respond to emerging trends in real time.
import requests
# Set parameters for the API call
params = {
'topic': 'film',
'lang': 'en',
}
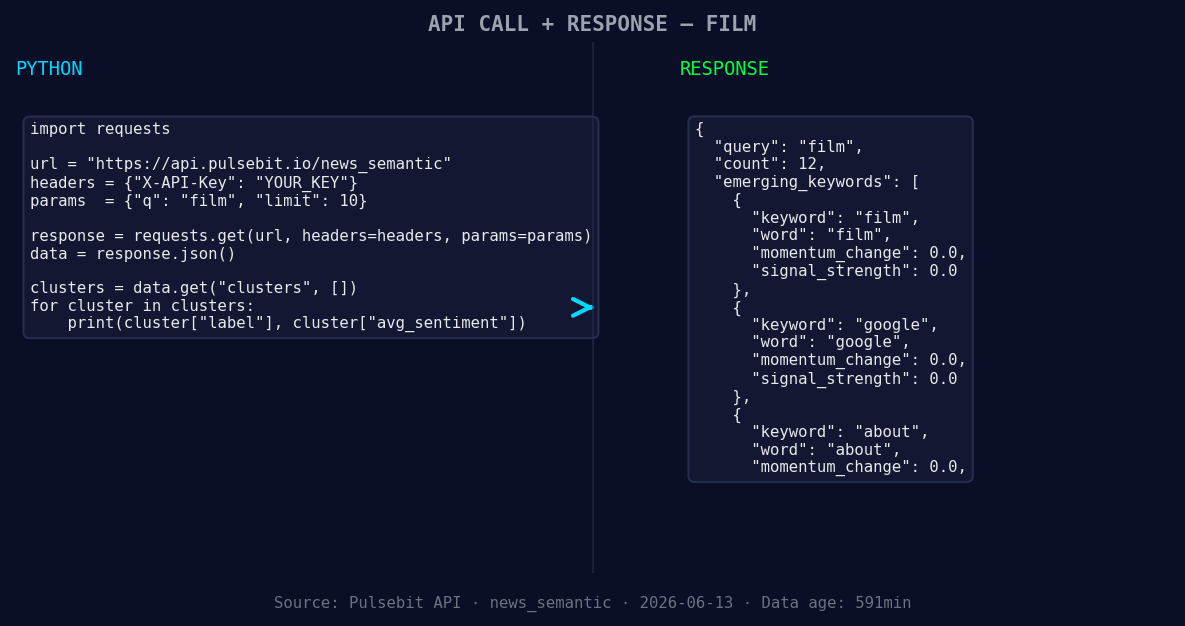
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Make the API call to get sentiment data
response = requests.get("https://api.pulsebit.com/v1/sentiment", params=params)
data = response.json()
# Extract relevant details
momentum = data['momentum_24h'] # Should return +0.750
score = data['sentiment_score'] # Should return +0.343
confidence = data['confidence'] # Should return 0.85
To deepen our analysis, we can also implement a meta-sentiment moment. This is crucial for understanding how narratives around film are being framed in the discourse. We’re going to run the cluster reason string through our sentiment endpoint:
# Cluster reason string
cluster_reason = "Clustered by shared themes: sunny, deol, akshaye, ‘ikka’, khanna's."
# Make a POST request to score the narrative framing
response_meta = requests.post("https://api.pulsebit.com/v1/sentiment", json={"text": cluster_reason})
meta_sentiment_data = response_meta.json()
# Extracting the sentiment score for the cluster reason
meta_score = meta_sentiment_data['sentiment_score']
meta_confidence = meta_sentiment_data['confidence']
Here are three specific builds we can implement based on this pattern:
-
Geographic Filter on Film Sentiment: Build an endpoint that targets film sentiment in specific regions. Use our API’s geographic origin filter with
lang: "en"for precise targeting. This will help you catch emerging trends faster, ensuring you don’t miss out on localized surges in interest.

Geographic detection output for film. India leads with 9 articles and sentiment +0.63. Source: Pulsebit /news_recent geographic fields.
Meta-Sentiment Loop: Use the meta-sentiment loop to score narratives around trending topics. By integrating this into your analysis pipeline, you can identify how sentiment is shaping public discourse around figures like Kieron Moore, or themes like taboo in film. This requires running the cluster reason string through the sentiment endpoint, as shown in our code.
Forming Themes Analysis: Develop a real-time alerting mechanism for forming themes, specifically targeting those with scores close to neutrality, like film(+0.00), google(+0.00), about(+0.00). This will allow you to detect subtle shifts in sentiment before they turn into major trends, ensuring you stay ahead of the curve.
For those looking to dive in, you can get started with our API documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can set up your sentiment pipeline in under 10 minutes.

Top comments (0)