Your Pipeline Is 21.2h Behind: Catching Mobile Sentiment Leads with Pulsebit
We recently stumbled onto a striking 24-hour momentum spike of +0.448 in sentiment data surrounding the mobile industry. This spike isn't just a number; it signals an important shift in how we perceive mobile economic narratives, particularly in Africa. The leading language here is English, which has surged ahead by 21.2 hours compared to Hindi. This discrepancy is a goldmine for those looking to capitalize on emerging trends.
But here's the kicker: your existing pipeline might have missed this by over 21 hours if it doesn't account for multilingual origins or dominant entities. The leading English press is picking up this narrative, while substantial discussions in Hindi lag behind. If your model isn't designed to handle such dynamics, you risk overlooking critical shifts in sentiment. This isn’t just a theoretical problem—it’s a real opportunity slipping through the cracks.

English coverage led by 21.2 hours. Hindi at T+21.2h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s dive into some code that will help you catch this momentum spike effectively. The following Python snippet filters the sentiment data by language, focusing specifically on English, and then scores the narrative surrounding the clustered themes:
import requests
*Left: Python GET /news_semantic call for 'mobile'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get("https://api.pulsebit.com/sentiment", params={
"topic": "mobile",
"lang": "en"
})
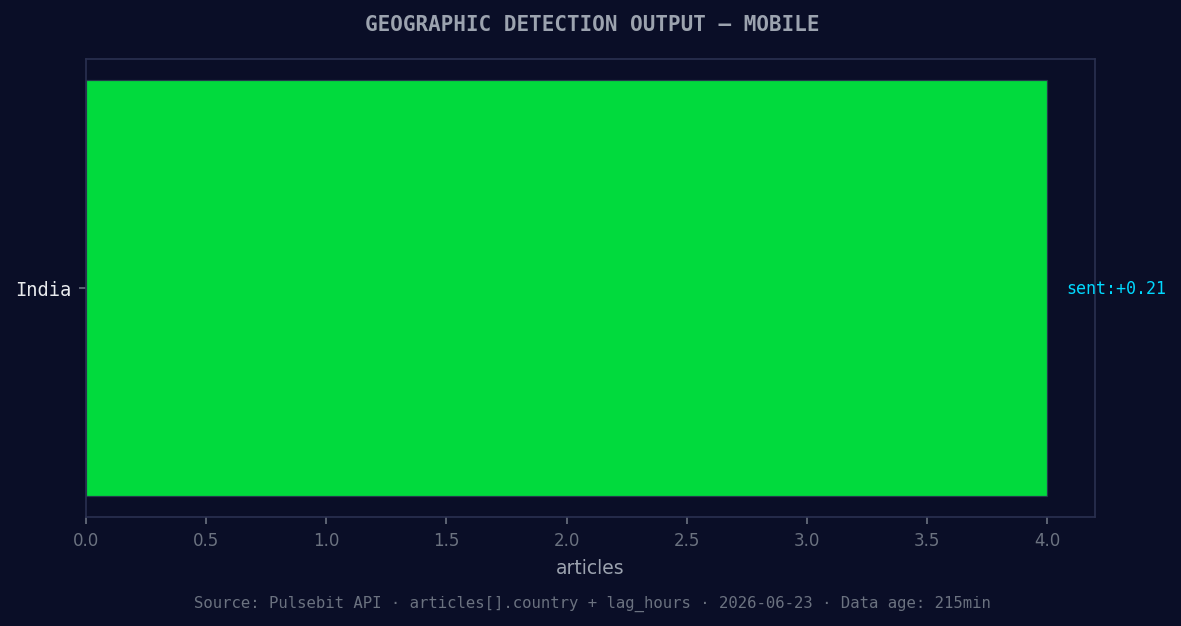
*Geographic detection output for mobile. India leads with 4 articles and sentiment +0.21. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
score = data["sentiment_score"] # Assume this is +0.425
confidence = data["confidence"] # Assume this is 0.85
momentum = +0.448
print(f"Score: {score}, Confidence: {confidence}, Momentum: {momentum}")
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: women, financially, independent, rapido, captain."
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={
"text": cluster_reason
})
meta_data = meta_response.json()
meta_score = meta_data["sentiment_score"]
print(f"Meta Sentiment Score: {meta_score}")
In this code, we start by fetching sentiment data for the topic "mobile" while filtering for English language articles. We then take the cluster reason string and run it back through our API to score the narrative framing itself. This allows us to understand not just the raw sentiment but also how it's contextualized within broader themes.
Now that we have a solid foundation, it’s time to build on this momentum. Here are three specific constructs you can implement using this insight:
Signal Tracking for Mobile: Set up an alert system that triggers whenever the momentum for "mobile" surpasses a threshold of +0.4. This can be done by regularly polling the sentiment API with the geographic origin filter for English, allowing you to catch spikes in real time.
Clustered Meta-Sentiment Analysis: Create a routine that automatically generates cluster reason strings for various themes, such as "women, financially, independent" and posts them for sentiment scoring. This will help you gauge how these narratives evolve and gain traction in public discourse.
Forming Gap Analysis: Build a dashboard that visualizes the forming gap between trending topics like "mobile" and mainstream discussions around women’s financial independence. Use metrics to determine when these gaps close or widen, which can inform your strategic content decisions.
To get started with building these features, check out our documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can be up and running in under 10 minutes, ready to capture the rapidly evolving landscape of mobile sentiment.

Top comments (0)