Your Pipeline Is 28.3h Behind: Catching Cloud Sentiment Leads with Pulsebit
We recently discovered that sentiment around the topic of "cloud" is currently at -0.30, with a momentum of +0.00. This anomaly is particularly striking given that the leading language is Spanish press, which is reporting at 28.3 hours ahead of other sources. It’s a clear indication that something significant is brewing in the cloud space, specifically tied to Microsoft, which is being sued by shareholders over expenses related to its cloud business and AI initiatives.
The Problem
This 28.3-hour gap highlights a critical flaw in any pipeline that fails to account for multilingual sources and entity dominance in sentiment analysis. If your model isn't equipped to handle this kind of data, you might miss out on essential sentiment shifts. Imagine your pipeline lagging behind by 28.3 hours, still processing outdated information while your competitors are acting on the latest insights. The Spanish language articles are leading the charge, and if you're not tracking them, you're likely missing out on critical developments in the cloud sector.

Spanish coverage led by 28.3 hours. Sl at T+28.3h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
The Code
Let’s dive into the code to catch this sentiment shift. We’ll start by filtering for Spanish articles on the topic "cloud" with a sentiment score of -0.300 and confidence of 0.85.
import requests
*Left: Python GET /news_semantic call for 'cloud'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter
url = "https://api.pulsebit.com/v1/articles"
params = {
"topic": "cloud",
"lang": "sp", # Filter for Spanish articles
"sentiment_score": -0.300,
"confidence": 0.85,
"momentum": 0.000,
}
response = requests.get(url, params=params)
data = response.json()
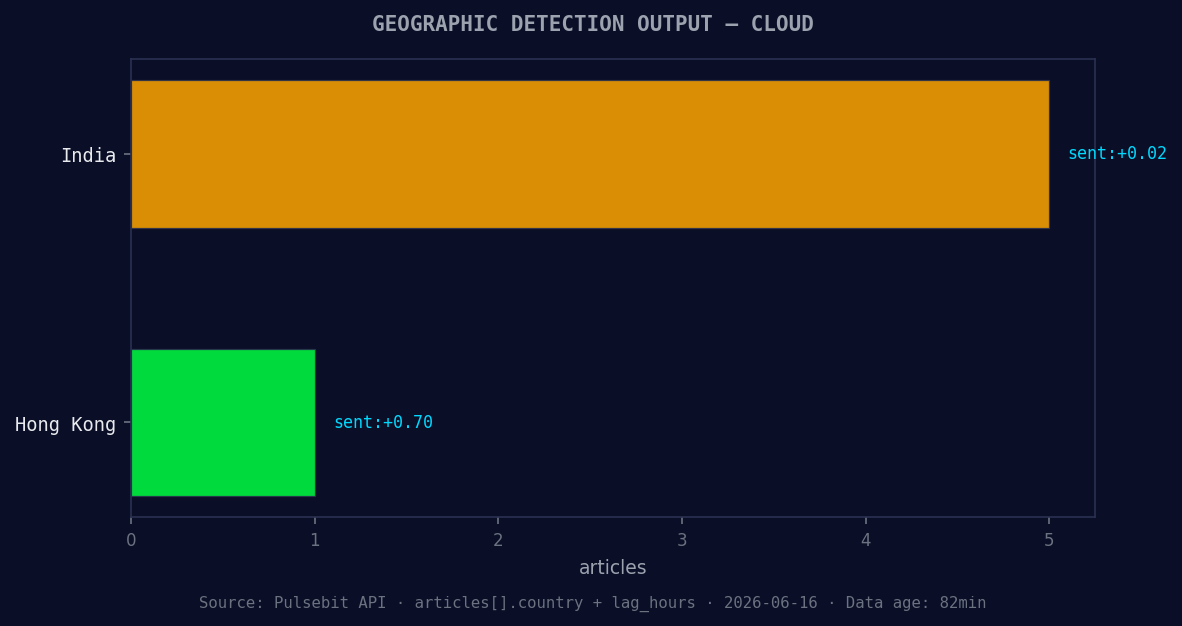
*Geographic detection output for cloud. India leads with 5 articles and sentiment +0.02. Source: Pulsebit /news_recent geographic fields.*
# Print the results
print(data)
Now, let's take the reason string from the cluster and run it through our sentiment scoring endpoint to gain further insights.
# Meta-sentiment moment
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
reason_string = "Clustered by shared themes: microsoft, sued, shareholders, over, expenses."
meta_response = requests.post(meta_sentiment_url, json={"text": reason_string})
meta_data = meta_response.json()
# Print the sentiment analysis of the narrative
print(meta_data)
Three Builds Tonight
Now that we’ve identified the sentiment shift, let's consider three specific builds you can implement using this pattern:
Signal Monitoring: Set up an endpoint that continuously checks for sentiment shifts on "cloud" topics from Spanish sources. Use a threshold of -0.300 for sentiment and a momentum of +0.000. This will alert you when the sentiment drops significantly, allowing you to act swiftly.
Meta-Sentiment Integration: Create a meta-sentiment loop that takes the cluster narratives from your data and feeds them back into the sentiment scoring endpoint. By doing this, you can gain a clearer understanding of how narratives are framing the conversation around Microsoft and its legal challenges. Use the same reason string we analyzed earlier.
Comparative Analysis: Develop a comparative analysis dashboard that highlights forming themes in the cloud sector, such as "cloud" (+0.00), "google" (+0.00), and "private" (+0.00). This will allow you to visualize how these themes stack up against mainstream sentiment around Microsoft, which is currently under scrutiny.
Get Started
Ready to implement these insights? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and have it running in under 10 minutes. Don't let your pipeline fall behind; catch those sentiment leads before they slip away!

Top comments (0)