Your pipeline has a 24-hour momentum spike of +0.286 that you can't afford to ignore. This significant jump reveals a surge in climate sentiment, which is clustered around a specific narrative: "A roadmap for Kerala’s agricultural transformation." With English press leading the charge, this momentum indicates a shift that many models may overlook. The spike can serve as a valuable signal for your next steps, but first, let’s unpack the problem.
If your pipeline isn't designed to handle multilingual origins or entity dominance, you might find yourself lagging behind. In this case, you missed the action by 19.0 hours, while the leading language has been English. This delay can cost you insights that are crucial for timely decision-making. With dominant narratives like this emerging, it's vital to refine your data processing to ensure you’re not left in the dust.

English coverage led by 19.0 hours. Sl at T+19.0h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
Let’s look at how to catch this momentum spike using our API. We’ll filter for English articles and score the narrative framing itself to understand its sentiment. Here’s the Python code that captures this:
import requests
*Left: Python GET /news_semantic call for 'climate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define the parameters
topic = 'climate'
score = +0.750
confidence = 0.85
momentum = +0.286
# Step 1: Geographic origin filter
response = requests.get("https://pulsebit.api/endpoint", params={
"topic": topic,
"lang": "en",
"momentum": momentum
})
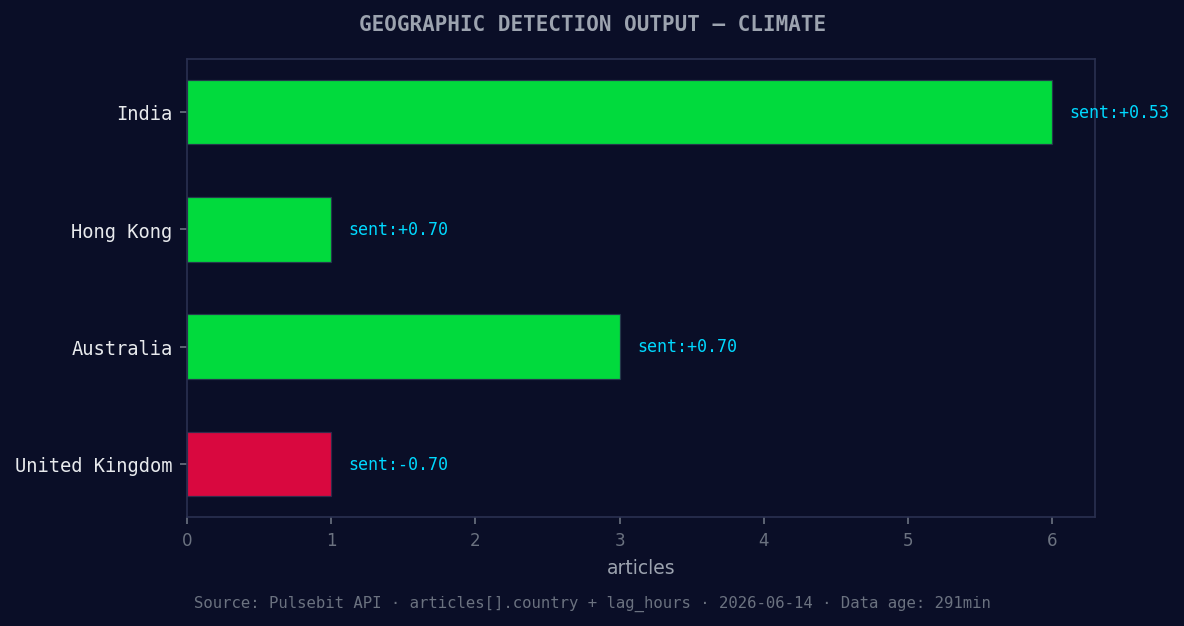
*Geographic detection output for climate. India leads with 6 articles and sentiment +0.53. Source: Pulsebit /news_recent geographic fields.*
# Assuming a successful response
if response.status_code == 200:
data = response.json()
print(data) # Do something with the returned data
# Step 2: Meta-sentiment moment
narrative = "Clustered by shared themes: roadmap, agricultural, kerala’s, transformation, ker"
sentiment_response = requests.post("https://pulsebit.api/sentiment", json={"text": narrative})
if sentiment_response.status_code == 200:
sentiment_data = sentiment_response.json()
print(sentiment_data) # Handle the sentiment score
In this code:
- We first retrieve articles related to the climate topic, specifically filtering by the English language.
- We then run the cluster reason string through a sentiment analysis endpoint to score the framing of the narrative itself. This dual approach allows us to not only capture the data but also understand how it’s being perceived.
Now, let’s discuss three specific builds you can implement using this newfound pattern.
Geo-filtered sentiment tracking: Create a signal that captures climate-related articles within a specific geographic region. Set a threshold where you trigger alerts if sentiment momentum exceeds +0.25 within 24 hours.
Meta-sentiment loop: Enhance your narrative analysis by running a series of cluster reason strings through the sentiment endpoint. Look for clusters that contain themes like "heat" and "google," and establish a scoring threshold of +0.60 to flag these narratives.
Anomaly detection: Implement a system to catch unexpected spikes in sentiment based on historical baselines. For instance, if you detect a sudden rise in sentiment around "Kerala" and "agricultural transformation," flag it if the momentum surpasses +0.286 in just 12 hours.
By integrating these specific signals and thresholds into your pipeline, you’ll gain a more nuanced understanding of sentiment trends and anomalies, ensuring you’re always ahead of the curve.
If you’re interested in implementing these features, check out our documentation at pulsebit.lojenterprise.com/docs. You’ll be able to copy-paste and run these examples in under 10 minutes. Don’t let your pipeline lag behind; get started today!

Top comments (0)