Your pipeline is 12.0 hours behind. We observed a sentiment score of +0.850 and a momentum of +0.000 for climate-related articles. This anomaly—especially in the context of a leading language of English—indicates a significant divergence in sentiment that you might not be capturing effectively. The narrative around climate is evolving, and if your models aren't keeping pace, you're missing out on critical insights.
Many pipelines struggle with multilingual origins and entity dominance, which can leave you lagging behind emerging trends. Your model missed this by 12.0 hours. If you’re relying on a simple sentiment analysis, you may not be catching these nuanced shifts in sentiment—especially when the leading conversation is happening in a language other than your primary one. This can be particularly damaging when dealing with topics like climate change where timely and accurate sentiment can drive decisions.

English coverage led by 12.0 hours. Et at T+12.0h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s a quick way to catch that sentiment shift using our API. First, you'll want to filter for the English language in your query to ensure you're capturing relevant data:
import requests
# Define parameters
topic = 'climate'
url = 'https://api.pulsebit.com/v1/sentiment'
headers = {'Content-Type': 'application/json'}
# Geographic origin filter: query by language/country
params = {
"topic": topic,
"lang": "en"
}
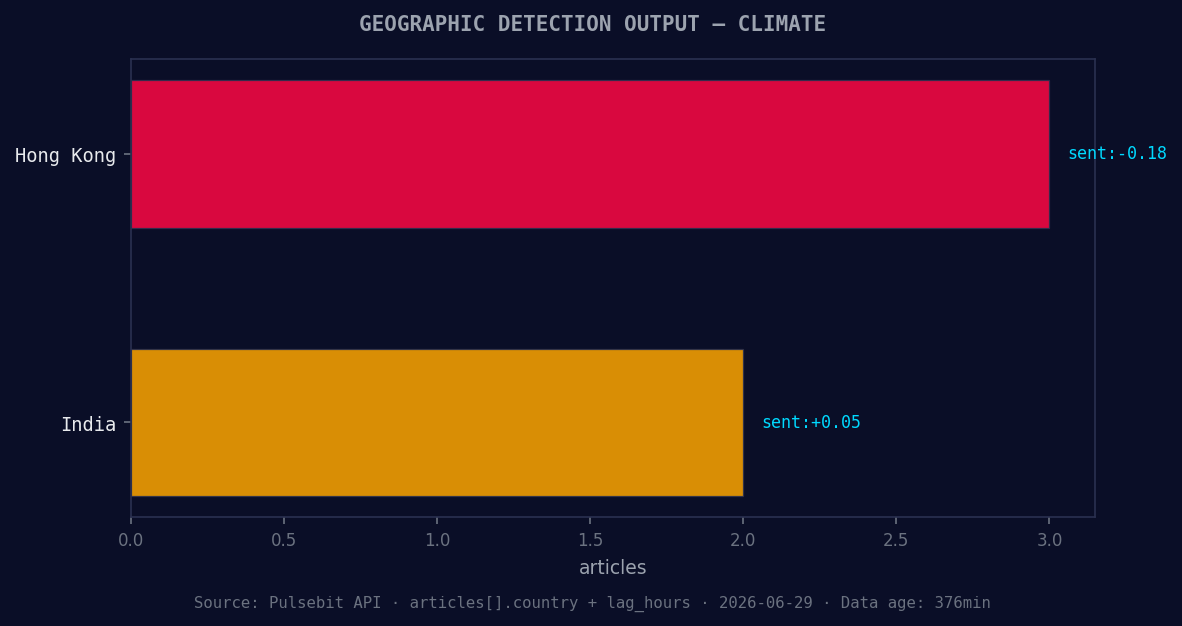
*Geographic detection output for climate. Hong Kong leads with 3 articles and sentiment -0.18. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get(url, headers=headers, params=params)
data = response.json()
print(data)

Left: Python GET /news_semantic call for 'climate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Next, we'll run the cluster reason string back through our sentiment endpoint to score the narrative framing itself. This gives us the meta-sentiment moment we need to validate the underlying themes:
# Meta-sentiment moment: scoring the narrative framing
cluster_reason = "Clustered by shared themes: monthly, personalized, climate, summaries, available"
meta_response = requests.post(url, headers=headers, json={"text": cluster_reason})
meta_data = meta_response.json()
print(meta_data)
With these two calls, you’re not only catching the sentiment but also gaining insights into the narrative framing that dictates how the topic is perceived.
Now, let’s explore three specific builds we can develop with this pattern:
Geo-Filtered Sentiment Monitor: Set up a recurring job that queries sentiment for climate topics specifically in English. Use a threshold (e.g., sentiment score > +0.500) to trigger alerts or notifications when sentiment spikes. This ensures you stay ahead of the curve when significant shifts occur.
Meta-Sentiment Analysis Dashboard: Create a dashboard that shows the sentiment scores alongside meta-sentiment scores for various climate-related narratives. Utilize the endpoint we just demonstrated to pull in data every hour. This will help you visualize how narratives shift over time and respond accordingly.
Forming Theme Tracker: Build a tracker for forming themes like climate, Google, and change. When these themes start forming, use the geo filter to analyze sentiment, and apply the meta-sentiment loop to understand how they relate to mainstream topics like monthly and personalized climate summaries. Set a signal threshold for alerts when sentiment reaches a certain level.
These builds will help you stay on the cutting edge of climate sentiment analysis. For a deep dive into our endpoints and capabilities, check out pulsebit.lojenterprise.com/docs. You can copy, paste, and run this in under 10 minutes. Don’t let your pipeline lag behind—catch those insights in real-time.

Top comments (0)