Your Pipeline Is 13.7h Behind: Catching World Sentiment Leads with Pulsebit
We just spotted a significant anomaly: a 24-hour momentum spike of +0.254 related to the topic of the "world." This spike stands out not only due to its magnitude but also because it's driven by English-language press coverage that has led by 13.7 hours. This lag highlights a gap in how we process multilingual sentiment data and reveals an opportunity for us to refine our pipelines.

English coverage led by 13.7 hours. Et at T+13.7h. Confidence scores: English 0.75, French 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
If your pipeline doesn't account for the nuances of multilingual origins or entity dominance, you might be missing critical insights. Imagine your sentiment analysis model missing a significant lead by 13.7 hours because it failed to prioritize English sources around this particular topic. Such lags can distort your understanding of global sentiment trends, especially when they are driven by dominant narratives in specific languages.
To catch this anomaly in your system, we can use our API to filter and analyze sentiment around key topics. Here’s how you can do that in Python:
import requests
# Define parameters for the API call
topic = 'world'
score = +0.147
confidence = 0.75
momentum = +0.254
lang = 'en'
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language
response = requests.get(f'https://api.pulsebit.com/sentiment?topic={topic}&lang={lang}')
data = response.json()
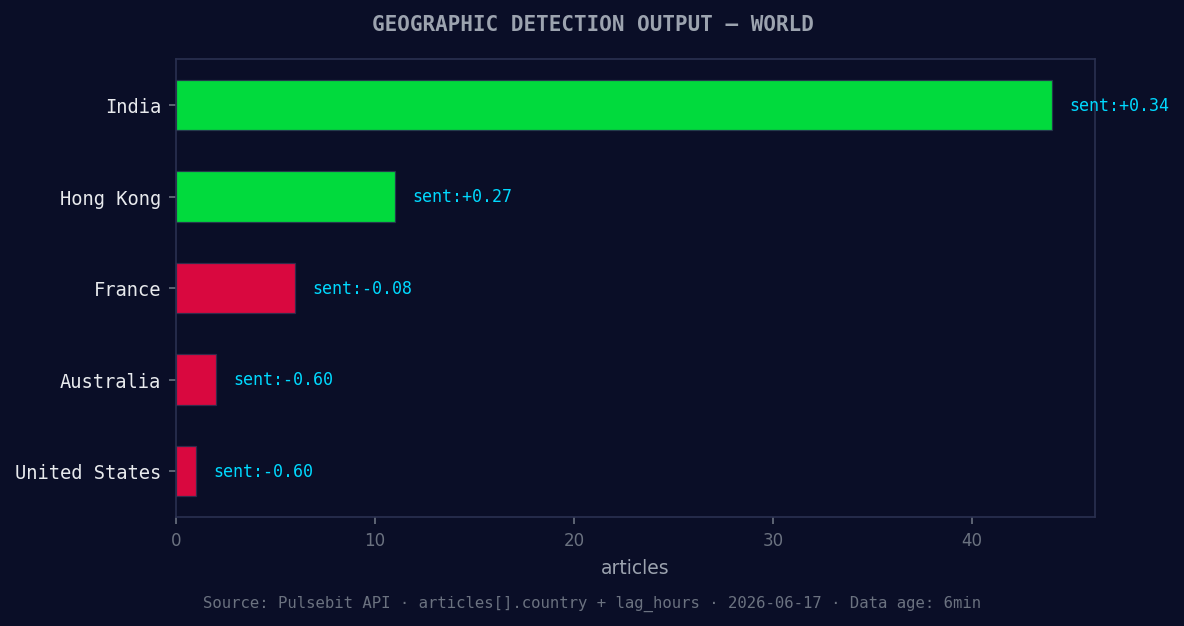
*Geographic detection output for world. India leads with 44 articles and sentiment +0.34. Source: Pulsebit /news_recent geographic fields.*
print(data) # This will show the sentiment analysis results
# Meta-sentiment moment: score the narrative framing itself
cluster_reason = "Clustered by shared themes: world, has, 193, countries, but."
sentiment_response = requests.post('https://api.pulsebit.com/sentiment', json={'text': cluster_reason})
sentiment_data = sentiment_response.json()
print(sentiment_data) # This gives insights into the framing of the narrative
In the above code, we first filter sentiment data by the English language to ensure we're capturing the most relevant information for our analysis. Then, we run the cluster reason string through our API to derive sentiment insights about the narrative framing itself.
Now, let’s look at three specific builds we can create using this pattern:
Anomaly Detection Signal: Set a threshold for momentum spikes where momentum > +0.2 in the English language. Use the endpoint
/sentimentto continuously monitor this signal and trigger alerts when it’s hit.Narrative Framing Analysis: Implement a pipeline that takes the input string from our clustered stories and runs them through the
/sentimentendpoint, scoring them for sentiment. This allows you to dynamically assess how narratives evolve around your main topics, such as the forming themes: "world", "cup", and "has".Real-time Geo-filtered Insights: Build a dashboard that visualizes sentiment trends for topics like "world" and compares them against mainstream mentions. Use our geo filter to focus on English sources and monitor how emerging themes develop over time. This can help you capture shifts in sentiment before they are reflected in broader discussions.
By leveraging these specific signals and insights using our API, you can ensure your sentiment analysis pipeline is agile and responsive to real-time trends.
Get started by exploring our documentation at pulsebit.lojenterprise.com/docs. You can copy and paste the code provided and run it in under 10 minutes to see these insights for yourself.

Top comments (0)