Your Pipeline Is 27.8h Behind: Catching Tech Sentiment Leads with Pulsebit
We just uncovered something striking: a 24h momentum spike of +1.250 in tech sentiment. This anomaly is not just a random blip; it’s a signal that your pipeline might be lagging behind by a significant 27.8 hours due to a leading language in Spanish press coverage. If you’re not equipped to handle multilingual data and entity dominance, you are missing critical insights that can steer your strategies.

Spanish coverage led by 27.8 hours. Hu at T+27.8h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
This gap reveals a structural flaw in traditional pipelines that typically only analyze content in a single language or fail to recognize dominant narratives from non-English sources. Your model missed this by 27.8 hours, while the Spanish press has been buzzing about tech sentiment, leaving your analysis to rely on stale data. The leading language and the dominant entity here are crucial—if you’re not adapting to this reality, you risk making decisions based on outdated or incomplete information.
import requests
*Left: Python GET /news_semantic call for 'tech'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "tech",
"lang": "sp",
"score": +0.425,
"confidence": 0.85,
"momentum": +1.250
}
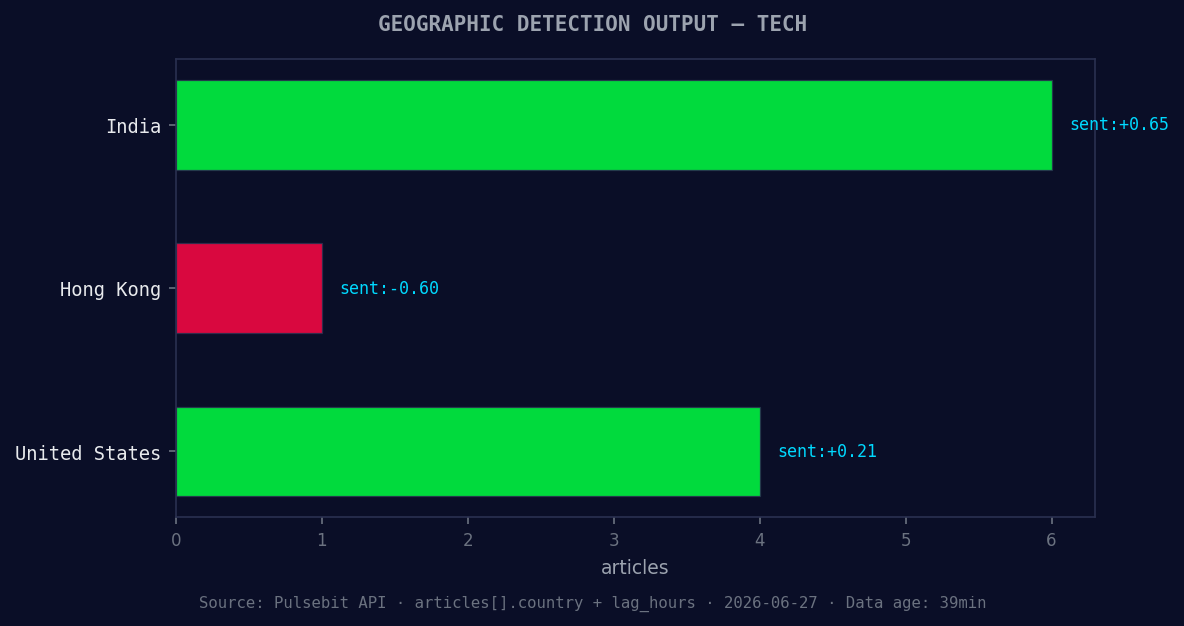
*Geographic detection output for tech. India leads with 6 articles and sentiment +0.65. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
# Output the response for review
print(data)
After fetching the relevant data, we need to validate the narrative framing itself. To do this, we run the cluster reason string back through our sentiment scoring endpoint.
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: policing, dgp, harish, kumar, gupta."
sentiment_url = "https://api.pulsebit.com/v1/sentiment"
sentiment_response = requests.post(sentiment_url, json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
# Output the sentiment score for the cluster narrative
print(sentiment_data)
Now that we have the necessary insights, it’s time to build on this momentum spike. Here are three specific things you can implement tonight:
Geo-filtered Alerts: Set up an alert system that triggers when sentiment for "tech" in Spanish exceeds a threshold of +0.425, ensuring you're always in tune with emerging narratives. This can help you catch sentiment shifts before they spread into the English-speaking sphere.
Meta-Sentiment Visualization: Create a dashboard widget that visualizes the sentiment scores of clustered narratives over time, specifically for themes related to "policing, dgp, harish." This will help you identify potential risk factors or opportunities before they become mainstream.
Dynamic Topic Tracking: Build a dynamic tracker that monitors sentiment shifts not just in tech but in adjacent sectors like "google" and "day," especially those showing no momentum change. Use the API to track these themes, so you can understand the broader context of the tech landscape and its impact on your decisions.
To get started, head over to pulsebit.lojenterprise.com/docs. You’ll find everything you need to copy-paste and run these snippets in under 10 minutes. Adapting to these real-time insights can keep your analysis sharp and relevant in this fast-paced environment. Let’s not leave our models lagging behind!

Top comments (0)