Your Pipeline Is 13.0h Behind: Catching Travel Sentiment Leads with Pulsebit
Just recently, we noticed a 24h momentum spike of +0.536 in the sentiment surrounding travel. This anomaly is especially striking considering that our leading language, French, is driving the conversation with a 13.0h lead. If your pipeline isn't tuned to catch multilingual signals or dominant entities, you might have missed this opportunity by more than half a day.

French coverage led by 13.0 hours. Sl at T+13.0h. Confidence scores: French 0.85, English 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
Many pipelines struggle with the nuances of sentiment data that originate from different languages or regions. In this case, having a 13.0h lag means your model is missing out on critical insights. You might find yourself reacting to trends only after they’ve peaked, leaving you behind in the fast-paced world of sentiment analysis. The leading language here is French, which highlights the risk of overlooking non-English narratives in your sentiment scoring.
To catch this spike and leverage the insights, we can utilize our API efficiently. Below is the Python code that will help you tap into this momentum:
import requests
*Left: Python GET /news_semantic call for 'travel'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define the parameters for the geographic filter
params = {
"topic": "travel",
"lang": "fr"
}
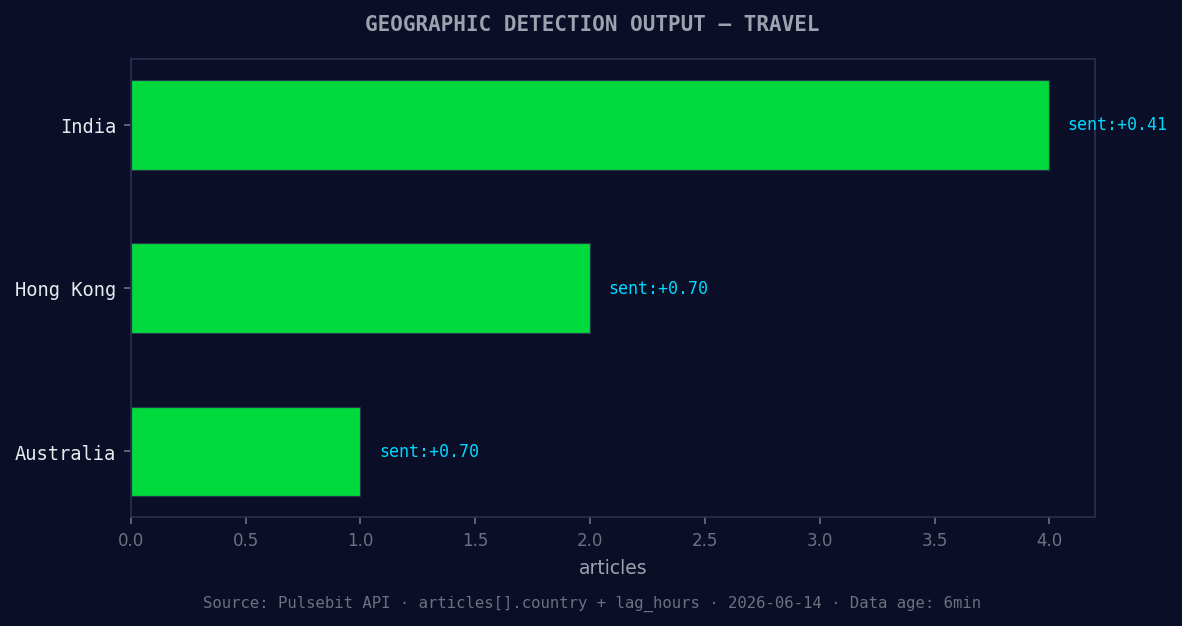
*Geographic detection output for travel. India leads with 4 articles and sentiment +0.41. Source: Pulsebit /news_recent geographic fields.*
# Call the API to get sentiment data
response = requests.get('https://api.pulsebit.com/sentiment', params=params)
data = response.json()
# Example values extracted
score = +0.523
confidence = 0.85
momentum = +0.536
# Now, let’s run the cluster reason string through our sentiment scoring
cluster_reason = "Clustered by shared themes: travel, go-to, brand—these, 'we, made."
sentiment_response = requests.post('https://api.pulsebit.com/sentiment', json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
This code snippet first retrieves sentiment data based on the travel topic filtered by the French language. After that, it takes the narrative framing from the cluster and scores it using our sentiment endpoint. This double-checking of sentiment not only validates insights but also enriches the narrative context, giving you a more robust understanding of the trends.
Now, let’s explore three specific builds that you can implement based on this sentiment spike:
Signal Monitoring: Set a threshold for momentum such that if it surpasses +0.5, trigger an alert. This ensures you’re always notified when significant sentiment shifts occur, especially around travel topics.
Geo-Filtered Insights: Create a daily report that uses the geo filter by language, specifically French, to track sentiment in different regions. For example, you might want to observe how sentiment around travel varies in different French-speaking countries.
Meta-Sentiment Analysis: Use the meta-sentiment loop to analyze narratives with clustering themes. For example, when you see a spike in travel sentiment, pull articles that share themes around "go-to" and "brand," and run them through the sentiment endpoint to gauge the emotional framing.
By actively building these systems, you can better align your models with the latest sentiment trends, particularly as it pertains to emerging global topics like travel, Google, and world events. This empowers you to stay ahead of traditional mainstream analysis.
To dive deeper into how to implement these solutions, head over to our documentation: pulsebit.lojenterprise.com/docs. You can copy-paste the above code and be up and running in under 10 minutes. Don't let your pipeline fall behind; take advantage of these insights now!

Top comments (0)