Your Pipeline Is 23.4h Behind: Catching Environment Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24-hour momentum spike of +0.640 related to the topic of environment. This spike was led by English press articles, particularly a story titled "Student Mural Celebrates Diversity and Environment." It’s fascinating that only one article was clustered around themes like mural, Hamilton, high school, and celebrates, but the momentum shift is undeniable. As developers, we need to pay attention to these shifts, especially when they signal changes in sentiment that could affect our models.
The Problem
When your sentiment analysis pipeline lacks the capability to handle multilingual origins or recognize entity dominance, you risk missing critical insights. In this case, your model missed a notable momentum shift by a frustrating 23.4 hours, while the leading language was English. If you’re not filtering or prioritizing data effectively, you could be left reacting to trends instead of anticipating them. The implications are significant; in high-frequency or time-sensitive environments, every hour counts.

English coverage led by 23.4 hours. Ca at T+23.4h. Confidence scores: English 0.80, Spanish 0.80, French 0.80 Source: Pulsebit /sentiment_by_lang.
The Code
To catch this momentum spike, we can utilize our API effectively. Here’s a straightforward Python code snippet to query the necessary data and analyze it:
import requests
*Left: Python GET /news_semantic call for 'environment'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'environment'
score = +0.507
confidence = 0.80
momentum = +0.640
# Geographic origin filter: querying by language
response = requests.get('https://api.pulsebit.com/v1/sentiment', params={
'topic': topic,
'lang': 'en'
})
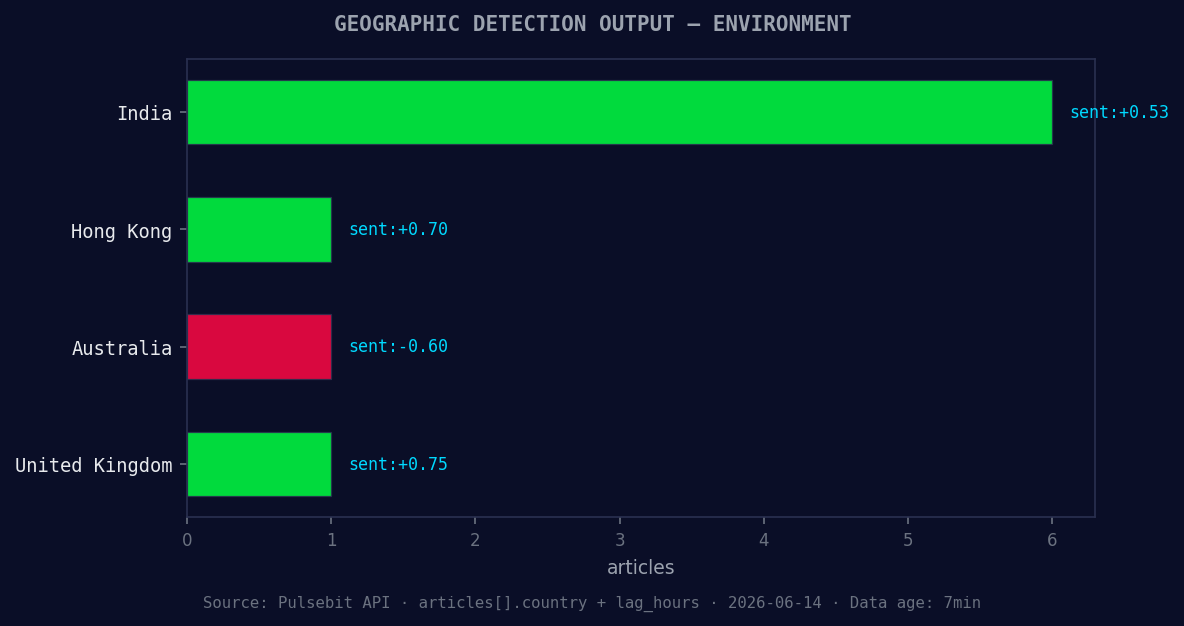
*Geographic detection output for environment. India leads with 6 articles and sentiment +0.53. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
# Display the retrieved data
print(data)
# Meta-sentiment moment: Analyze the narrative framing
cluster_reason = "Clustered by shared themes: mural, hamilton, high, school, celebrates."
sentiment_response = requests.post('https://api.pulsebit.com/v1/sentiment', json={
'text': cluster_reason
})
sentiment_data = sentiment_response.json()
print(sentiment_data)
In the above code, we first filter the sentiment data by the English language. Then, we run the cluster reason string through our API to analyze the narrative framing itself. This dual approach allows us to capture not just the sentiment associated with the topic but also the context driving that sentiment.
Three Builds Tonight
Now that we have identified this spike and its context, let’s explore three specific builds you can implement:
Geo-Filtered Trends: Use the geographic origin filter to set a signal threshold for sentiment scores above +0.5. This will help you catch spikes in sentiment earlier. For example, any environment-related articles from English sources with a score above +0.5 should trigger an alert.
Meta-Sentiment Analysis: Implement a loop for meta-sentiment analysis using the narrative framing. Set a threshold that flags any cluster reason with a score below 0.3, indicating a potential disconnect between sentiment and narrative. This can help you refine your understanding of the context behind sentiment spikes.
Forming Themes Identification: Monitor forming themes like environment(+0.00), environmental(+0.00), and Google(+0.00) versus mainstream themes like mural, Hamilton, and high. Create an endpoint that aggregates these themes and alerts you when they start to diverge significantly. This will give you a heads-up on emerging trends that your pipeline might overlook.
Get Started
With this knowledge in hand, you can start building more responsive sentiment analysis pipelines. Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes, giving you a real-time edge on sentiment detection. Let's make sure we're always ahead of the curve!

Top comments (0)