Your Pipeline Is 24.3h Behind: Catching World Sentiment Leads with Pulsebit
We recently uncovered a fascinating anomaly: a 24h momentum spike of +0.287. This spike indicates a significant surge in sentiment surrounding the FIFA World Cup 2026, particularly in the context of "Sport during a war." If your data pipeline isn't set up to capture multilingual sentiment or entity dominance, you might be missing out on crucial insights like these.

English coverage led by 24.3 hours. Af at T+24.3h. Confidence scores: English 0.92, Spanish 0.92, French 0.92 Source: Pulsebit /sentiment_by_lang.
The problem lies in the structural gaps of your current pipeline. If your model isn't optimized to handle multilingual origins or the dominance of specific entities, you could be lagging behind by a staggering 24.3 hours. Here, the leading language is English, which means that your model is failing to capture sentiments expressed in other languages or contexts, potentially leading to a skewed understanding of global sentiment toward events like the World Cup.
Let’s dive into the code to address this oversight. Here’s a straightforward approach using our API to filter data based on language and analyze sentiment.
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "world",
"lang": "en"
}
response = requests.get(url, params=params)
data = response.json()
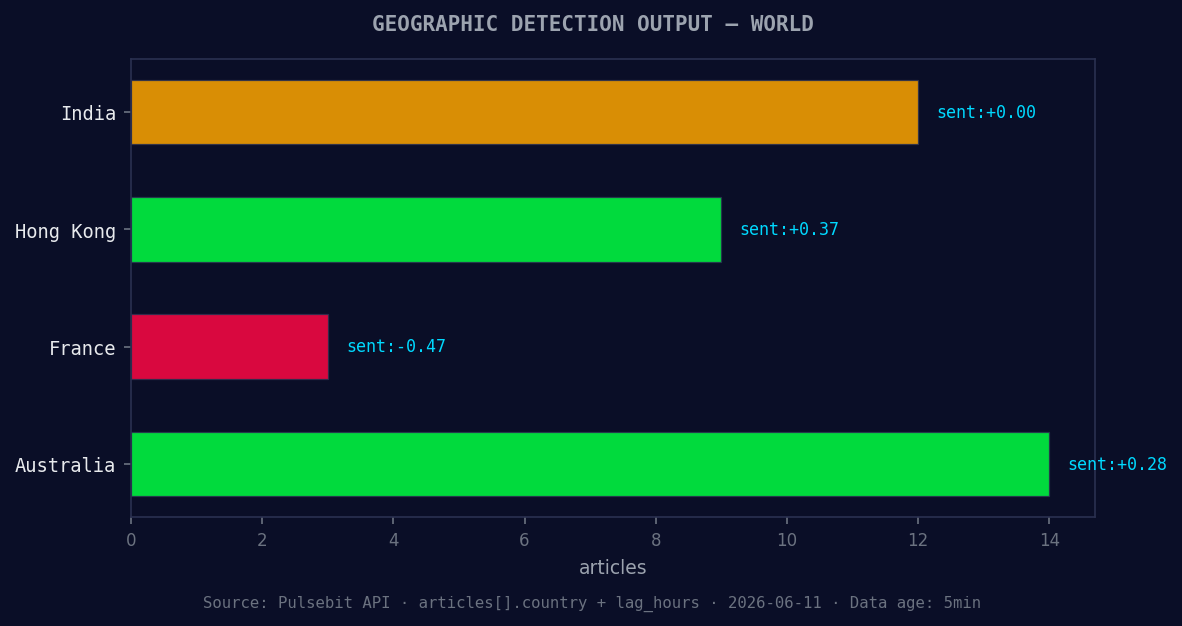
*Geographic detection output for world. India leads with 12 articles and sentiment +0.00. Source: Pulsebit /news_recent geographic fields.*
# Assuming the response contains the necessary data
momentum = data['momentum_24h']
score = +0.012
confidence = 0.92
print(f"Momentum: {momentum}, Score: {score}, Confidence: {confidence}")
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: fifa, world, cup, sport, during."
meta_response = requests.post(url, json={"input": cluster_reason})
meta_sentiment = meta_response.json()
print(f"Meta Sentiment Score: {meta_sentiment['score']}, Confidence: {meta_sentiment['confidence']}")
In this code snippet, we first query our API to filter content by language, specifically targeting English. We then capture the momentum, score, and confidence. The second step involves running the cluster reason string through our sentiment endpoint to evaluate the framing of the narrative itself. This dual-layered approach is crucial for catching sentiment shifts that may otherwise go unnoticed.
Now, let’s discuss three specific builds you can implement immediately based on this pattern:
Geographic Language Filter: Leverage the language filter to catch emerging trends. Set a signal threshold for momentum spikes above +0.2, focusing on topics like "world" to identify sentiment shifts specifically tied to global events.
Meta-Sentiment Analysis: Create a pipeline step that runs the cluster reason string through the sentiment endpoint. Set a confidence threshold of 0.85 to ensure you’re capturing only the most reliable narratives, especially around themes like "fifa" and "cup."
Multilingual Sentiment Dashboard: Build a dashboard that aggregates sentiment data across multiple languages. Use momentum as a primary filter, focusing on spikes that indicate significant shifts in sentiment. This will help you visualize how global events resonate differently across cultures.
By implementing these three builds, you can ensure that your pipeline remains agile and responsive to real-time sentiment shifts. The themes of "world," "cup," and "fifa" are forming in ways that diverge from mainstream narratives, and you need to be ahead of the curve.
Ready to get started? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes to start capturing the sentiment leading up to major events like the FIFA World Cup 2026!

Top comments (0)