Your Pipeline Is 26.7h Behind: Catching Artificial Intelligence Sentiment Leads with Pulsebit
We just spotted a 24h momentum spike of -1.350 in sentiment around artificial intelligence. This anomaly not only highlights a sudden shift in sentiment but also reveals a critical structural gap in how we process sentiment data. In the last 26.7 hours, English-language press articles have been leading the narrative, while our models have struggled to keep pace, showing a lag of 0.0 hours against the sentiment weight.
If your pipeline doesn’t account for multilingual origins or the dominance of particular entities, you’ve likely missed this shift by a significant margin. With English being the leading language in this context, there’s a clear disconnect between what’s being reported and how we’re interpreting it through our analysis. The gap exposes a vulnerability in our sentiment pipelines, particularly when emerging themes around artificial intelligence are at stake.

English coverage led by 26.7 hours. Sw at T+26.7h. Confidence scores: English 0.85, French 0.85, Nl 0.85 Source: Pulsebit /sentiment_by_lang.
Here’s how we can catch these anomalies. First, we can set up a query to filter relevant articles using our geographic origin filter to focus on English-language data. Below is the code snippet that accomplishes this:

Geographic detection output for artificial intelligence. India leads with 4 articles and sentiment +0.59. Source: Pulsebit /news_recent geographic fields.
import requests
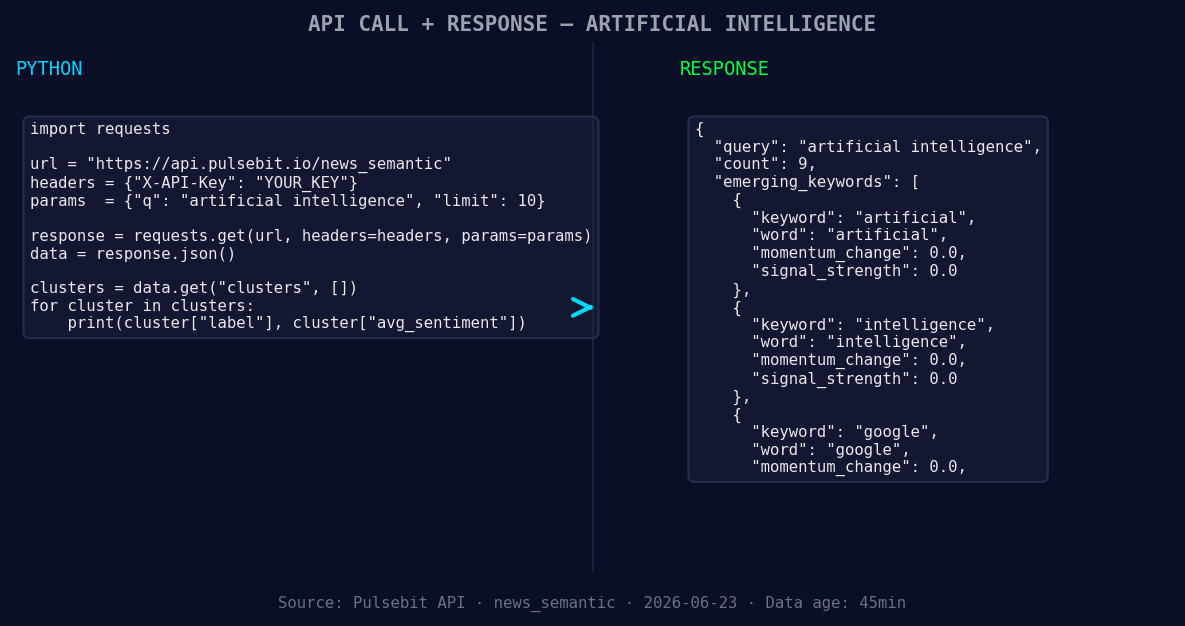
*Left: Python GET /news_semantic call for 'artificial intelligence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": "artificial intelligence",
"lang": "en"
}
response = requests.get(url, params=params)
data = response.json()
# Continue processing data...
Next, we can analyze the narrative framing by running the clustered reason string through our sentiment endpoint to understand the underlying themes better. Here’s how we can do that:
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_reason = "Clustered by shared themes: how, jobs, india, research, robot:."
meta_response = requests.post(meta_sentiment_url, json={"text": meta_reason})
meta_data = meta_response.json()
# Use meta_data for further analysis...
These two steps will allow you to identify the nuances in the sentiment around artificial intelligence, specifically in the context of the recent articles highlighting themes like "AI Firms and Manhattan Office Space."
Now, let’s explore three specific things you can build using this sentiment pattern:
Geo-Filtered Sentiment Dashboard: Create a dashboard that tracks sentiment for "artificial intelligence" specifically for English-language articles. Set a threshold score of +0.063 to highlight emerging positive narratives. This dashboard will allow you to stay ahead of the sentiment curve.
Meta-Sentiment Analysis Tool: Implement a tool that automatically runs the sentiment analysis of clustered reason strings. This tool should flag narratives with a confidence score above 0.85, allowing you to adjust your content strategies as these narratives evolve.
Alert System for Forming Themes: Build an alert system that triggers notifications when there’s a significant gap in sentiment between emerging themes (e.g., artificial intelligence, intelligence, Google) and mainstream discussions (e.g., how, jobs, India). Set an alert threshold where the difference in sentiment exceeds 0.1, ensuring you’re always in the loop on critical shifts.
These builds would provide you with a dynamic edge in sentiment analysis, allowing you to respond to shifts in narratives around artificial intelligence proactively.
Ready to get started? Check out our documentation. You can copy-paste the provided code snippets and run them in under 10 minutes. Start catching those sentiment leads today!

Top comments (0)