Your Pipeline Is 28.3h Behind: Catching World Sentiment Leads with Pulsebit
We recently uncovered a significant anomaly in the sentiment data: a 24h momentum spike of +0.257. This surge indicates a noteworthy shift in global sentiment regarding the topic of "world." However, what stands out even more is that the leading language influencing this spike is French, peaking at 28.3 hours ahead of Italian sentiment. This delay in recognizing the French narrative could cost you critical insights if your pipeline isn't equipped to handle multilingual data effectively.

French coverage led by 28.3 hours. Italian at T+28.3h. Confidence scores: French 0.75, English 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
In the realm of sentiment analysis, missing a lead by 28.3 hours is not just inconvenient; it’s a structural gap that can undermine your model's effectiveness. This delay means that while you might be reacting to emerging trends in one language, another language has already set the stage for the conversation. With the French press leading the charge on this topic, your model would have missed this momentum spike entirely. This is a stark reminder of the importance of multilingual capabilities in your data pipeline.
To catch this momentum spike, let’s dive into some Python code that utilizes our API. We’ll filter for the French language and retrieve relevant sentiment data on the topic "world."
import requests
*Left: Python GET /news_semantic call for 'world'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/sentiment',
params={
'topic': 'world',
'lang': 'fr',
'score': +0.139,
'confidence': 0.75,
'momentum': +0.257
}
)
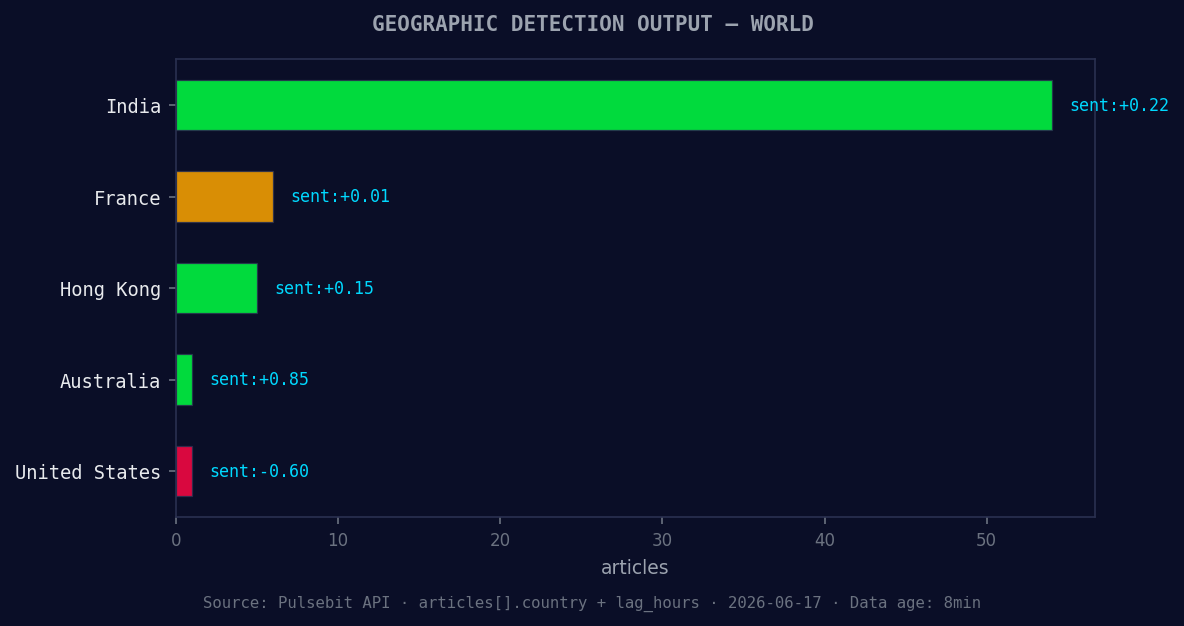
*Geographic detection output for world. India leads with 54 articles and sentiment +0.22. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data) # Inspect the response
The next step is to analyze the narrative framing of this sentiment. We’ll send a string related to the cluster reason back through the sentiment API to quantify its overall sentiment.
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: world, has, 193, countries, but."
response_meta = requests.post(
'https://api.pulsebit.com/sentiment',
json={'text': cluster_reason}
)
meta_data = response_meta.json()
print(meta_data) # Inspect the meta sentiment response
With these two snippets, we can capture the momentum spike and its narrative framing effectively.
Now that we’ve caught the spike, let’s discuss three specific builds you can implement using this pattern:
Multilingual Sentiment Pipeline: Build a dedicated endpoint that captures momentum spikes across multiple languages. Set a threshold of +0.250 for momentum and filter for the French language to ensure you don't miss out on early signals.
Cluster Reason Analyzer: Create a function that leverages the meta-sentiment loop to analyze the sentiment of cluster reasons. Set a threshold of +0.150 for sentiment score. This will allow you to frame narratives around emerging trends more effectively.
Real-time Alerts for Forming Themes: Implement a monitoring system that sends alerts when topics such as "world" (+0.00), "cup" (+0.00), or "has" (+0.00) form in your dataset. Integrate the geo filter for French articles and set a metric that triggers a notification when sentiment momentum surpasses +0.200.
By incorporating these builds, you can ensure your models stay relevant and responsive to sentiment shifts, particularly in a multilingual context.
Ready to explore this further? Head over to our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the above code and get it running in under 10 minutes. Don’t let your pipeline fall behind again.

Top comments (0)