Your Pipeline Is 20.8h Behind: Catching Climate Sentiment Leads with Pulsebit
We’ve stumbled upon an intriguing anomaly: a 24h momentum spike of +0.439 in climate sentiment. This significant shift highlights a growing urgency surrounding climate-related discussions, particularly in English press, which leads by 20.8 hours over Hindi sources. With two articles focusing on the UNICEF report about Indian children and climate hazards, this spike presents an opportunity for us to reevaluate our sentiment pipelines.
The problem here is clear. If your pipeline doesn’t handle multilingual origins or entity dominance effectively, you could be missing out on critical insights. Your model missed this momentum spike by a staggering 20.8 hours, as the leading language (English) was left behind while Hindi was gaining traction. This lag can lead to missed opportunities, especially in fast-moving domains like climate discussions.

English coverage led by 20.8 hours. Hindi at T+20.8h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To help you catch these signals, here’s how we can leverage our API. We’ll start by filtering for climate-related topics specifically for English content:
import requests
# Define the parameters
params = {
"topic": "climate",
"score": -0.122,
"confidence": 0.85,
"momentum": +0.439,
"lang": "en" # Geographic origin filter
}
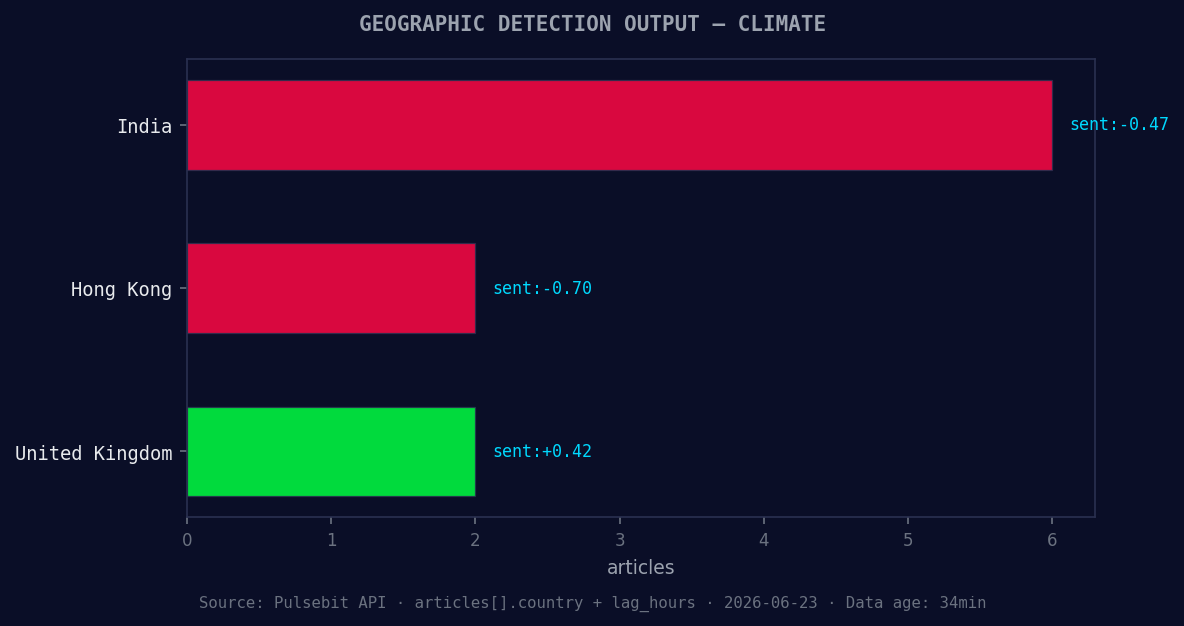
*Geographic detection output for climate. India leads with 6 articles and sentiment -0.47. Source: Pulsebit /news_recent geographic fields.*
# Make the API call
response = requests.get('https://api.pulsebit.lojenterprise.com/v1/sentiment', params=params)
data = response.json()
print(data)

Left: Python GET /news_semantic call for 'climate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.
Next, we need to analyze the narrative framing surrounding this spike. We’ll send the cluster reason string back through our sentiment analysis endpoint to gain deeper insights:
# Meta-sentiment moment
cluster_reason = "Clustered by shared themes: climate, indian, children, extreme, heat."
meta_sentiment_response = requests.post(
'https://api.pulsebit.lojenterprise.com/v1/sentiment',
json={"text": cluster_reason}
)
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
This analysis allows us to capture not just the sentiment score but also the nuances in how the narrative is being framed.
Now, let's discuss three actionable builds we can implement with this data.
Geo-Filtered Alert System: Set a threshold of +0.3 momentum for English-language articles related to climate. Create a notification system that alerts you when this threshold is crossed, indicating a significant shift in sentiment that could warrant immediate action.
Meta-Sentiment Analysis Loop: Use the meta-sentiment loop to generate daily insights on clustered topics. Set up a cron job that pulls the latest cluster narratives around topics like “climate” and “heat,” providing you with a daily digest of sentiment shifts that can inform your content strategy.
Forming Themes Dashboard: Build a dashboard that tracks forming themes in real-time. Create an endpoint that pulls data on forming themes like climate, google, and heat, comparing them to mainstream narratives. Set a threshold of 0.0 momentum to highlight emerging discussions before they gain traction.
To get started, visit our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code snippets provided and run them in under 10 minutes to tap into these insights. Don't let your pipeline lag behind—stay ahead of the momentum!

Top comments (0)