Your model just missed a critical insight: a sentiment spike of +0.16 with a momentum of +0.00, observed at 12.2 hours behind the leading language, French. This anomaly highlights a crucial gap where travel sentiment around the World Cup is surging, yet your pipeline isn't capturing these nuances. The lag is telling; if you're not accounting for multilingual origins, you may be missing out on significant trends. For instance, if your model is primarily tuned for English, you might overlook the early enthusiasm that's brewing in the French-speaking community.

French coverage led by 12.2 hours. Et at T+12.2h. Confidence scores: French 0.75, English 0.75, Spanish 0.75 Source: Pulsebit /sentiment_by_lang.
Now, let’s dig deeper into the problem. Your pipeline’s inability to handle multilingual sentiment means you’re missing insights like this by over 12 hours. If you’re focusing solely on dominant entities like English narratives, you risk losing valuable context. This isn’t just a theoretical gap; it’s a practical shortfall that can lead to missed opportunities in understanding sentiment dynamics, especially around major events like the World Cup.
To catch this travel sentiment lead, we can leverage our API effectively. Here’s how to do it:
import requests
# Define the topic and parameters for the API call
topic = 'travel'
score = +0.160
confidence = 0.75
momentum = +0.000
*Left: Python GET /news_semantic call for 'travel'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: Query by language (French)
response = requests.get(
'https://api.pulsebit.com/v1/sentiment',
params={
'topic': topic,
'lang': 'fr',
'score': score,
'confidence': confidence,
'momentum': momentum
}
)
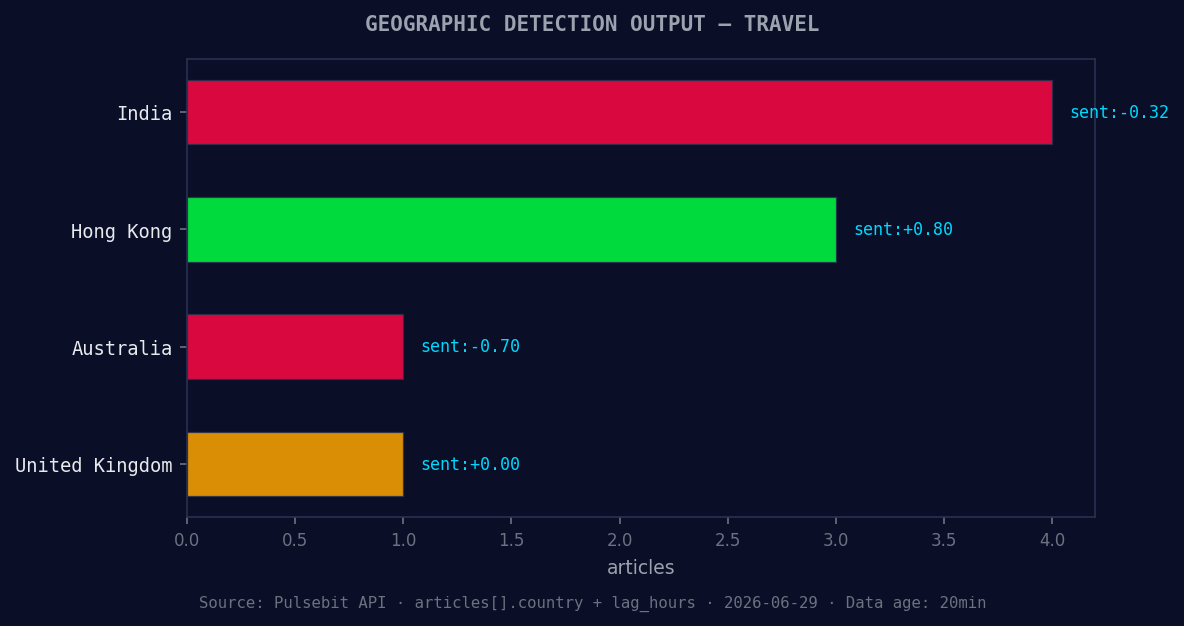
*Geographic detection output for travel. India leads with 4 articles and sentiment -0.32. Source: Pulsebit /news_recent geographic fields.*
# Check the response
data = response.json()
print(data)
Next, we want to run the cluster reason string through our sentiment analysis. This part is crucial to understand the narrative framing itself.
# Meta-sentiment moment: Analyze the narrative
cluster_reason = "Clustered by shared themes: world, cup, travel, grind, real."
sentiment_response = requests.post(
'https://api.pulsebit.com/v1/sentiment',
json={
'text': cluster_reason
}
)
# Output the meta sentiment analysis
meta_sentiment_data = sentiment_response.json()
print(meta_sentiment_data)
Using these two API calls, we can effectively capture the sentiment dynamics surrounding the travel topic and analyze the narrative surrounding the World Cup.
Let’s consider three specific builds we could implement with this pattern:
Travel Sentiment Tracker: Set a signal threshold for travel sentiment at +0.10 with a geo filter for French-speaking regions. This would allow us to capture early indicators of sentiment changes before they trend in English.
Cluster Narrative Analyzer: Utilize the meta-sentiment loop on narratives clustered around major events. For example, input thematic clusters like "world, cup, travel" to score how effectively these narratives resonate across different languages.
Real-time Travel Insights Dashboard: Combine the geo filter and meta-sentiment loop to create a real-time dashboard that alerts you when sentiment for travel spikes in specific regions, helping you stay ahead of mainstream trends.
By implementing these builds, we can ensure that our pipelines are not just reactive but proactive in capturing the nuances of sentiment across languages and themes.
If you're ready to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy, paste, and run this in under ten minutes. Let’s close that 12.2-hour gap together!

Top comments (0)