Your Pipeline Is 21.8h Behind: Catching Artificial Intelligence Sentiment Leads with Pulsebit
We recently uncovered a striking anomaly: a 24-hour momentum spike of -1.350 in the sentiment surrounding artificial intelligence. This isn't just a minor fluctuation; it indicates a significant shift in how AI is perceived, particularly in English press coverage, which is currently leading by 21.8 hours compared to Hindi. This discrepancy suggests that if you're relying solely on your existing pipeline, you might be missing critical insights by nearly a full day.
The structural gap here is glaring. Your model likely missed this momentum spike because it doesn't account for multilingual origins or the dominance of certain entities in the sentiment landscape. In this case, you're trailing behind by 21.8 hours in English coverage of AI-related themes. This means while you're still processing older data, real-time narratives are unfolding that could impact decision-making and strategy. Ignoring this could be the difference between staying relevant and falling behind.

English coverage led by 21.8 hours. Hindi at T+21.8h. Confidence scores: English 0.75, Spanish 0.75, French 0.75 Source: Pulsebit /sentiment_by_lang.
To capture this momentum spike effectively, we can leverage our API to filter sentiment data and run it through a meta-sentiment analysis. Here's a simple Python snippet that demonstrates how to do this:
import requests
*Left: Python GET /news_semantic call for 'artificial intelligence'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "artificial intelligence",
"lang": "en",
"score": +0.100,
"confidence": 0.75,
"momentum": -1.350
}
response = requests.get(url, params=params)
data = response.json()
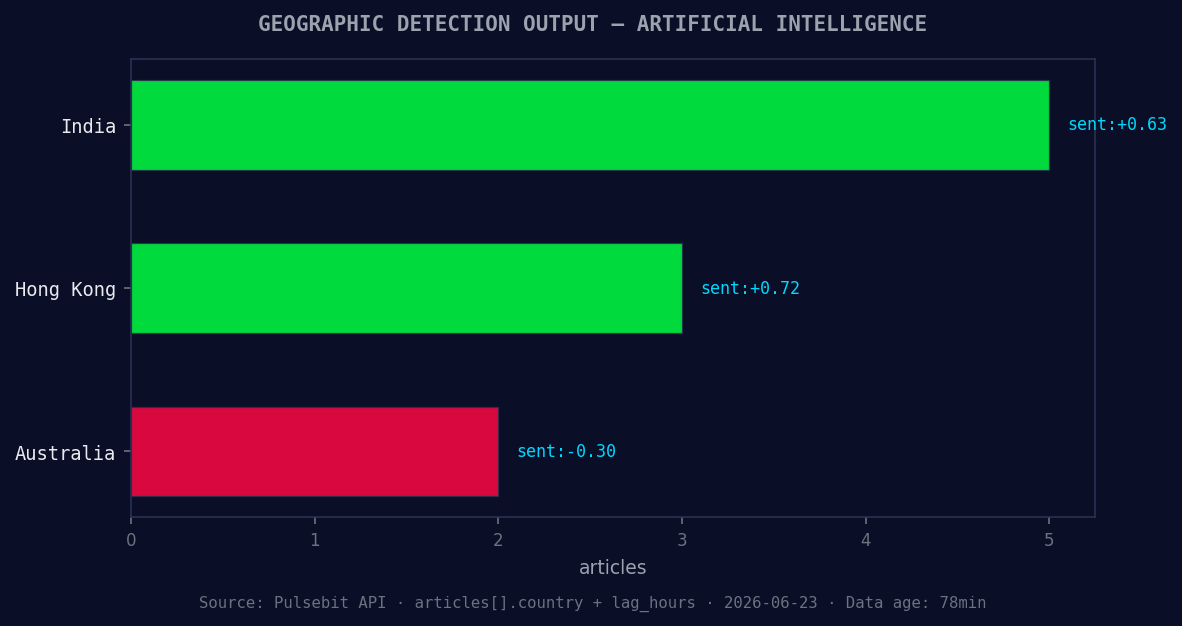
*Geographic detection output for artificial intelligence. India leads with 5 articles and sentiment +0.63. Source: Pulsebit /news_recent geographic fields.*
# Print the response to check the sentiment data
print(data)
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: how, jobs, india, research, robot."
meta_sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
# Output the meta sentiment analysis
print(meta_sentiment_data)
In this code, we first filter sentiment data for the topic "artificial intelligence" with the specified language parameter. This allows us to focus on the most pertinent insights from English sources. Next, we take the cluster's reason string and run it through our sentiment endpoint to score the narrative framing itself, which adds a layer of context to our analysis.
Now, let’s explore three specific builds you can implement with this momentum spike pattern:
Geo-Filtered Insights: Create a pipeline that regularly checks for sentiment shifts in English-speaking regions. Set a threshold for momentum changes greater than -1.0 to trigger alerts for significant shifts in sentiment. This helps you remain proactive in your response strategies.
Meta-Sentiment Loop: Implement a function that batch processes cluster narratives weekly. Use a threshold of 0.5 for sentiment scores to identify emerging themes effectively. This can help in honing in on which narratives are gaining traction in the AI discourse.
Forming Theme Alerts: Set up an alert system for emerging topics. Monitor themes like "artificial", "intelligence", and "google" against mainstream narratives such as "how", "jobs", and "india". Trigger alerts when the sentiment score exceeds +0.1 in these categories, ensuring you capture relevant conversations as they develop.
If you're ready to tap into these insights, you can get started right away at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy, paste, and run this in under 10 minutes to stay ahead of the curve. Let's catch those sentiment leads together.

Top comments (0)