Your Pipeline Is 28.9h Behind: Catching Finance Sentiment Leads with Pulsebit
We recently discovered a striking anomaly: a 24h momentum spike of +0.416 in the finance sector. This spike was particularly interesting as it was led by English press articles, which were clustered around the story titled "Chile Finance Minister Backs Off Key Budget Goal as Debt Rises." What makes this even more compelling is that our pipeline would have missed this significant momentum shift by nearly 29 hours if it were solely relying on Portuguese sources, given the 28.9h lead of English content.
When your model doesn't handle multilingual origins or entity dominance properly, you risk missing critical shifts in sentiment. In this case, you would have missed the opportunity to react to a notable financial development, as the leading language was English, carrying a 28.9-hour advantage over Portuguese. This delay could be detrimental if your strategy relies on timely data to make decisions. Your pipeline needs to adapt to the multilingual landscape of finance, or you risk being left behind.

English coverage led by 28.9 hours. Portuguese at T+28.9h. Confidence scores: English 0.85, Nl 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch such anomalies, we need a Python script that leverages our API. Below is how we can set this up.
import requests
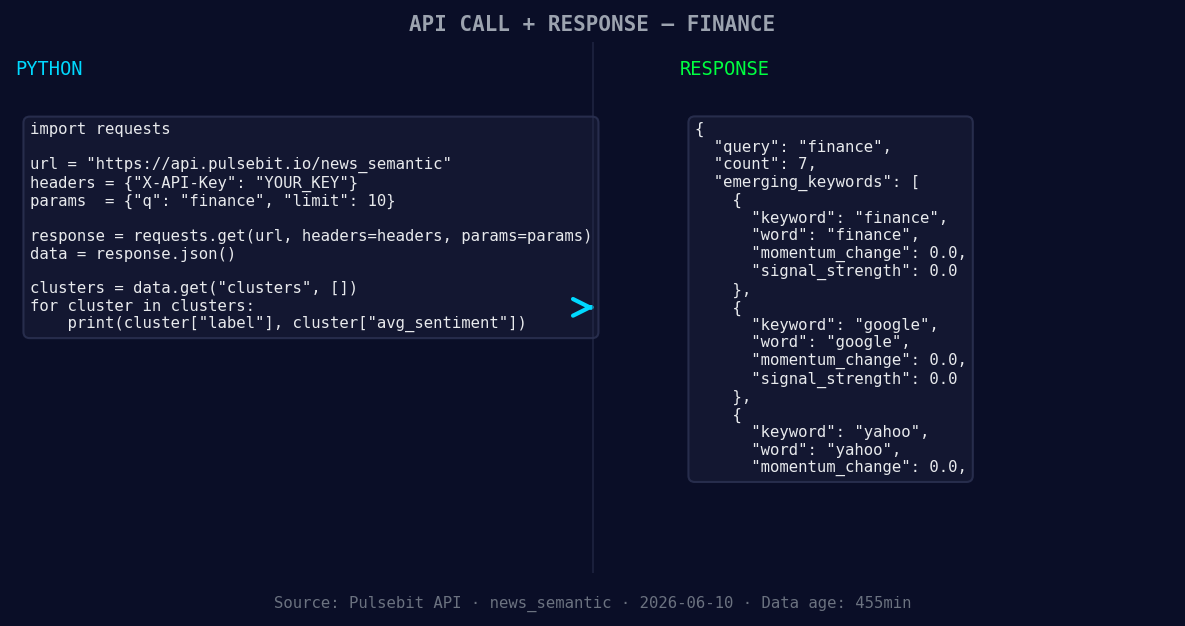
*Left: Python GET /news_semantic call for 'finance'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define parameters
topic = 'finance'
score = +0.000
confidence = 0.85
momentum = +0.416
language = 'en'
# Step 1: Geographic origin filter
response = requests.get(f"https://api.pulsebit.io/sentiment?topic={topic}&lang={language}")
data = response.json()
print(data)
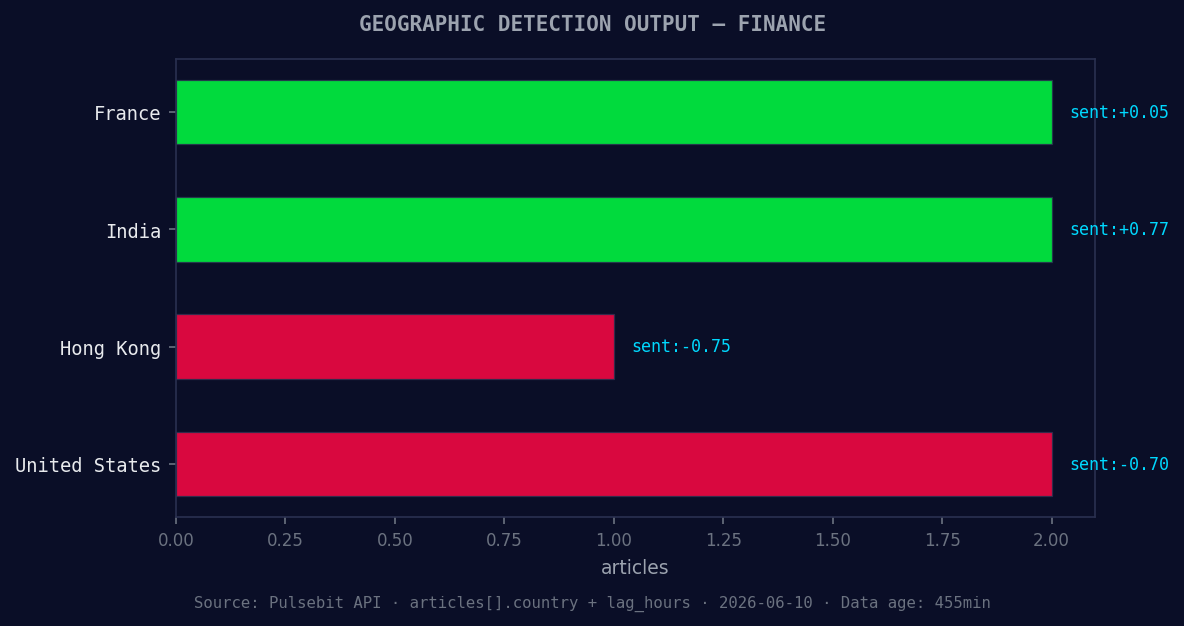
*Geographic detection output for finance. France leads with 2 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
clusters_reason = "Clustered by shared themes: finance, budget, goal, chile, minister."
sentiment_response = requests.post("https://api.pulsebit.io/sentiment", json={"text": clusters_reason})
sentiment_data = sentiment_response.json()
print(sentiment_data)
In the first part of the code, we're filtering our query by language to ensure we're capturing sentiment from the leading English articles. The response will provide insights into how the finance topic is performing in that specific language. In the second part, we analyze the narrative framing by sending the cluster reason string through our sentiment endpoint. This is crucial because understanding the thematic context around the sentiment can guide decision-making.
Now that we have a handle on catching the momentum spike, here are three specific builds you can create based on this pattern:
Sentiment Alert System: Build a system that triggers alerts when the momentum score exceeds a certain threshold, say +0.300, specifically for finance articles in English. Use the geographic origin filter to ensure you're only monitoring the most relevant content.
Meta-Sentiment Analysis Dashboard: Create a dashboard that visualizes the meta-sentiment of clustered articles. Use the loop from our API to continuously pull in the latest narratives clustered by relevant themes such as finance, budget, and goal. This will keep you updated on how emerging stories are shaping sentiment.
Comparison of Language Sentiments: Develop a comparative analysis tool that measures sentiment scores between English and Portuguese articles on the same topic. Set a threshold to trigger when the difference exceeds 0.200, highlighting potential areas of opportunity or risk.
If you want to dive deeper into building these capabilities, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy, paste, and run the code provided above in under 10 minutes to start leveraging these insights in your own projects.

Top comments (0)