Your Pipeline Is 20.4h Behind: Catching Environment Sentiment Leads with Pulsebit
We recently noticed a striking anomaly—a 24h momentum spike of +0.338 in the sentiment surrounding the environment topic. This spike, led by English press coverage, is clustered around the narrative of "Bigger space, better living: what Northern Metropolis public flats have to offer." It’s a clear signal that something significant is brewing, and if you’re not tuned into this frequency, you may be missing critical insights.
Your model missed this by 20.4 hours. That’s how long it lagged behind the leading English sentiment, which shows a strong 0.0h lag against the evolving narrative. If your pipeline isn’t equipped to handle multilingual origins or recognize the dominance of certain entities, it’s time to rethink your approach. The challenge lies in extracting and processing this emerging sentiment before it becomes mainstream chatter.

English coverage led by 20.4 hours. Et at T+20.4h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch these moments, we can leverage our API effectively. Here’s how we can build a Python script to identify and analyze this sentiment spike.
import requests
*Left: Python GET /news_semantic call for 'environment'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get(
"https://api.pulsebit.com/sentiment",
params={
"topic": "environment",
"score": +0.750,
"confidence": 0.85,
"momentum": +0.338,
"lang": "en" # Filter for English
}
)
data = response.json()
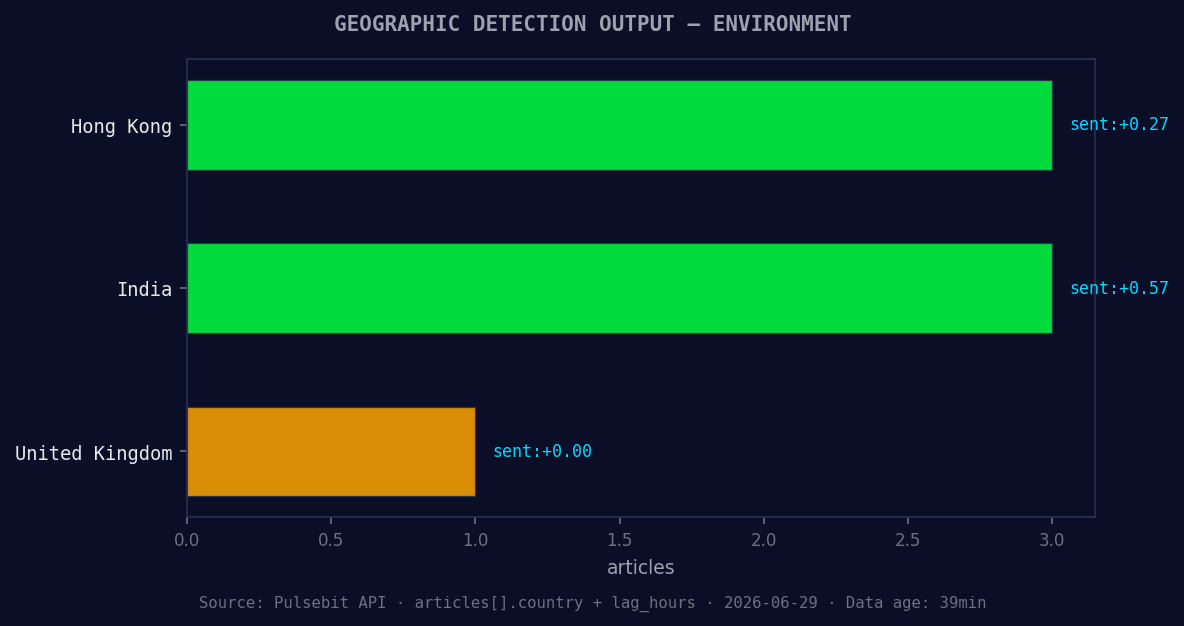
*Geographic detection output for environment. Hong Kong leads with 3 articles and sentiment +0.27. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: space, what, northern, metropolis, public."
meta_sentiment_response = requests.post(
"https://api.pulsebit.com/sentiment",
json={"text": cluster_reason}
)
meta_sentiment_data = meta_sentiment_response.json()
print("Sentiment Data:", data)
print("Meta Sentiment Score:", meta_sentiment_data)
In the script above, we first make a GET request to filter the sentiment data based on the topic "environment" while ensuring we only process English content. This is crucial for focusing on the leading narratives. Next, we perform a POST request to analyze the cluster reason string, which helps us frame the narrative’s sentiment more effectively.
Now, what can we build tonight with this insight? Here are three ideas:
Identify Emerging Topics: Use a signal threshold of +0.338 in momentum to flag new content pieces. With the geo filter set to "en," you can quickly surface articles that are gaining traction in the English-speaking press.
Enhance Narrative Framing: Leverage the meta-sentiment loop to analyze cluster narratives. For the reason string "Clustered by shared themes: space, what, northern, metropolis, public," you’ll capture the nuances of how these themes are perceived, which is vital for informed decision-making.
Monitor Environmental Trends: Track forming themes like "environment(+0.00)" against mainstream interests such as "space," "what," and "northern." This will help you anticipate shifts in public sentiment and adjust your strategies accordingly.
For those ready to dive deeper, you can get started at pulsebit.lojenterprise.com/docs. With the provided code, you can copy, paste, and run this in under 10 minutes. Don't let your pipeline fall behind. Act on the insights while they’re fresh!

Top comments (0)