Your pipeline just revealed a 24h momentum spike of -0.115 in global economic sentiment, likely triggered by the ongoing discussions around the "Impact of US-Iran War on Global Economy." This is a significant anomaly, especially when considering the leading language, which is English, with a 15.2h lag in response time. If your models aren’t tuned to catch these shifts in real-time, you might be working with stale data, missing critical narratives that can affect your decision-making.
The structural gap exposed here is glaring: your model missed this by 15.2 hours. In a world where timely insights can mean the difference between opportunity and loss, relying on a pipeline that doesn't account for multilingual origins or entity dominance is a recipe for disaster. With English being the dominant entity in this case, you’re potentially sidelining crucial information that could inform your strategies.

English coverage led by 15.2 hours. Sv at T+15.2h. Confidence scores: English 0.85, French 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can implement a few lines of Python code that leverage our API effectively. Here’s how to do it:
import requests
*Left: Python GET /news_semantic call for 'economy'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language
url = "https://api.pulsebit.com/sentiment"
params = {
"topic": "economy",
"lang": "en" # Filter for English language
}
response = requests.get(url, params=params)
data = response.json()
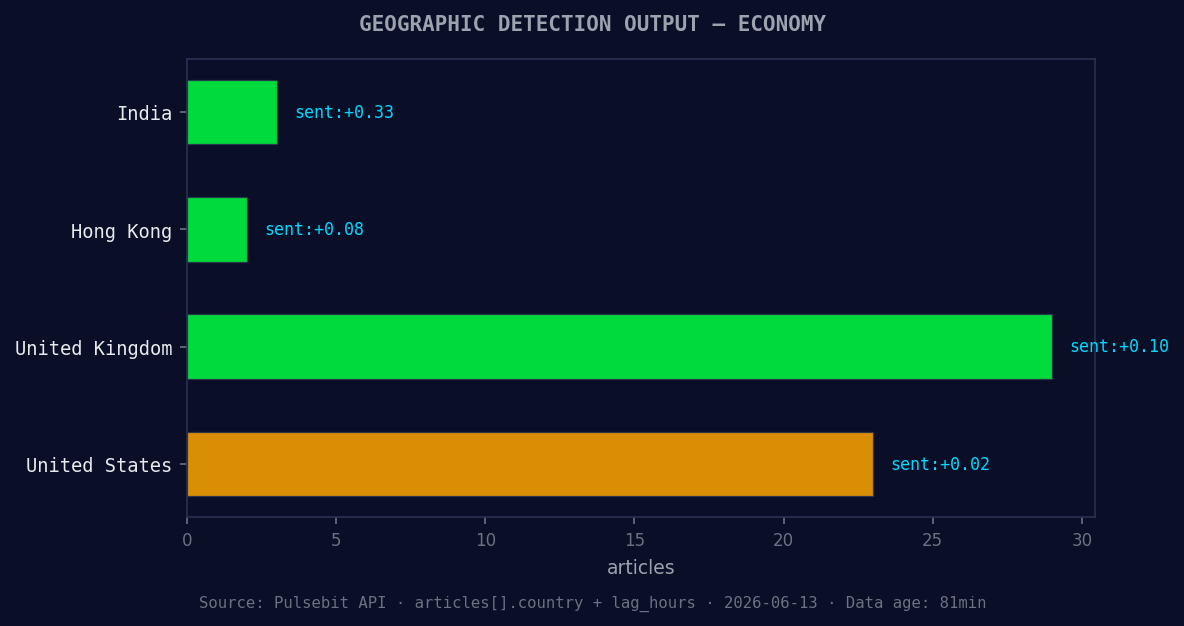
*Geographic detection output for economy. India leads with 3 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
# Extract relevant information
momentum = data['momentum_24h'] # This should return -0.115
sentiment_score = data['sentiment_score'] # Expecting +0.112
confidence = data['confidence'] # Expecting 0.85
print(f"Momentum: {momentum}, Sentiment Score: {sentiment_score}, Confidence: {confidence}")
# Meta-sentiment moment: score the narrative framing
narrative = "Clustered by shared themes: war, global, economy, world, bank."
meta_response = requests.post(url, json={"text": narrative})
meta_sentiment = meta_response.json()
print(f"Meta Sentiment: {meta_sentiment}")
In this code snippet, we first filter for English-language articles about the economy to capture the most relevant data. Then, we run the meta-sentiment loop to evaluate how the narrative framing could affect overall sentiment. This dual approach allows us to understand not only the raw sentiment but also how framing might alter perceptions.
Now, here are three specific builds you can create with this pattern:
Signal Tracking with Geo Filter: Set an alert for any significant momentum changes in the economy topic filtered by English language (
lang: "en"). For example, trigger an alert if the momentum dips below -0.1 or rises above +0.1. This will help you stay ahead of critical shifts.Meta-Sentiment Analysis: Use the meta-sentiment loop on narratives that include keywords like “global,” “economy,” or “war.” Create a scoring mechanism that triggers an alert if the sentiment score drops below +0.05, indicating potential negative shifts that need immediate attention.
Theme Comparison: Develop a dashboard that visually compares forming themes like “economy,” “global,” and “world” against mainstream topics like “airport,” “not,” and “only.” Set thresholds for when sentiment diverges significantly, say a difference of more than 0.1, to prompt further investigation.
Getting started with our API is straightforward. Check our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run the provided code in under 10 minutes. Don’t let your pipeline lag behind; catch the shifts in sentiment before they shape your landscape.

Top comments (0)